






Source Code repository backup
How important are your GitHub repositories? Or any git based repositories such as GitLab, BitBucket, etc. It’s not entirely unlikely that we either have the crown jewels in regards to company intellectual property stowed in a repository as well as a load of hobby projects in our own repositories. All in all a pretty important selection of data, being hosted on these services, which can be thought of as a SaaS service for our or our organization’s source code.
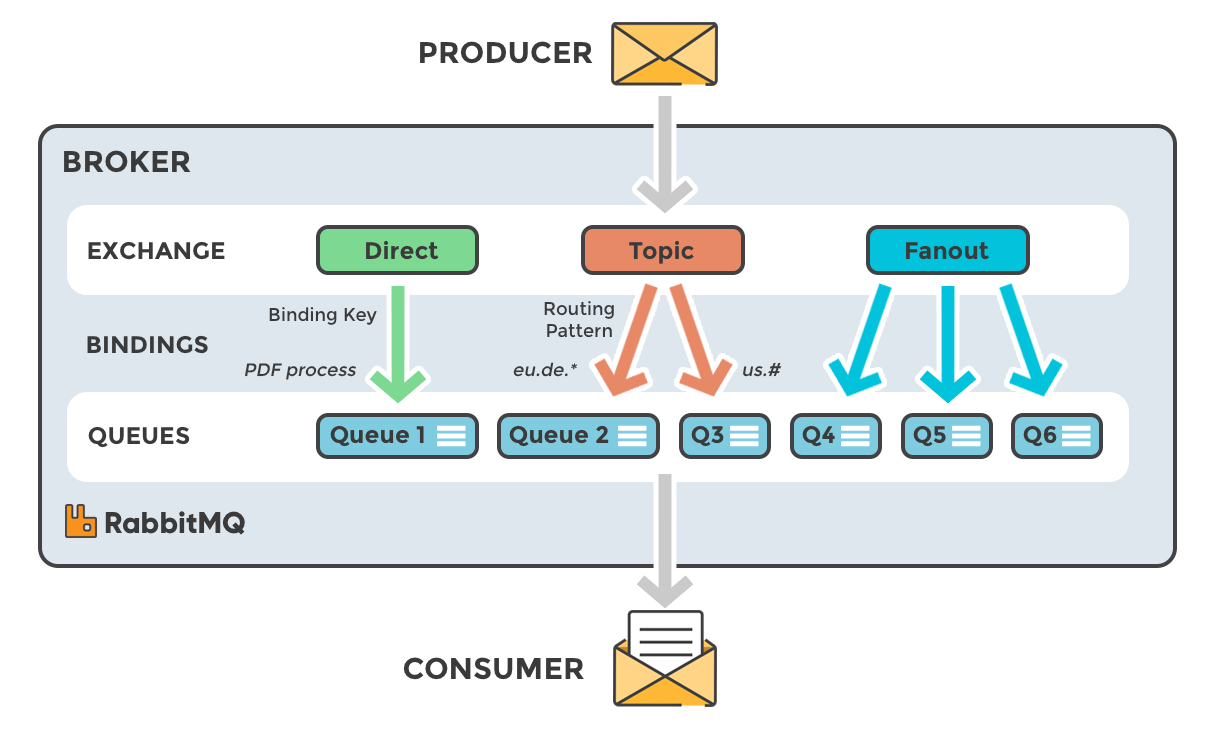
When we think about SaaS for example Microsoft 365, we know there is a shared responsibility model - Microsoft will keep the infrastructure up and running and make sure you have access to a certain SLA etc but the data is yours… if you decide to delete an email or an item stored on your OneDrive, then Microsoft is under no obligation to help get your data back up and running. This is why we need to backup Microsoft 365… So what about GitHub, GitLab, and BitBucket to name a few?
I am not in anyway picking on GitHub, rather all SaaS providers will have a terms of service, so here is a link to the specifics for GitHub
One thing worth noting is, like any service account, security is a concern. You should protect this with multi-factor authentication (MFA), but this is not a barrier against certain malicious activity, namely internal malice.
We have named one area of risk, but there are possibly others to consider:
- What if the service is not available? Probably not the end of the world, the data is safe providing things come back up.
- What if repositories suddenly become a paid for option only within your git-based service?
- What if someone was able to gain access to code and make changes not captured or tracked, and then software was then released to the public (probably extends the use case for source code repository backup)?
- What about a mistake in a developer workflow?
Hopefully you get the point I am trying to make, some people will also say well we have a copy of the code on our laptops. Do you really want to rely on that when bad things are or have happened? Can you be absolutely sure you have absolutely everything? All of them issues and wiki pages you have had for many years on your repositories?
Before we do move on, GitHub also have a page in their docs called Backing up a repository which talks about using Git, third party tools or the API to back things up.
What are my options?
We could continue as normal and assume that my source code repository is just fine and nothing bad will happen to me. Alternatively, maybe a git clone --mirror https://github.com/EXAMPLE-USER/REPOSITORY.git is a good enough. This approach is only going to get that source code, not the wiki and other areas of the repository.
We could incorporate the above into a script and then let our backup tool of choice maybe pick that file up on a schedule, again this might be sufficient.
Maybe we could create another script that interacts with the API to again pull down the data we want to protect including the wiki, issues and discussions of our repository. Which then is picked up by a broader backup job.
Or, perhaps the best option, we can protect our source code using Kasten plus a Kanister blueprint with an open source project called gickup.
The Goal
I will say now that this is a work-in-progress and a look at the art of the possible of both Kanister blueprints and how this can be used to orchestrate other third-party tools with Kasten to provide an orchestrated way to protect different workloads.
The goal of this project is to provide a template for using Gickup within a Kubernetes cluster and then leveraging Kasten K10 to orchestrate Source Code Repository backups to an Object Storage location, which can be immutable and thus protected from ransomware attacks.
To achieve this we are going to create the following in our Kubernetes cluster, in a dedicated namespace.
gickup-deployment.yaml - Uses an image that has gickup binary and kando to ensure we can backup and then send our data to our Object Storage location.
gickup-config.yaml - contains configuration on our source, destination and logging
gickup-secret.yaml - contains our GitHub Secret but this could also contain any other sensitive information.
gickup-pv-pvc.yaml A volume to store our initial backup chain.
This is a work in progress and there is a potential that with some of the native functions available in Kanister we could possibly not have a deployment consistently running but only run the pod when the backup orchestration is taking place.
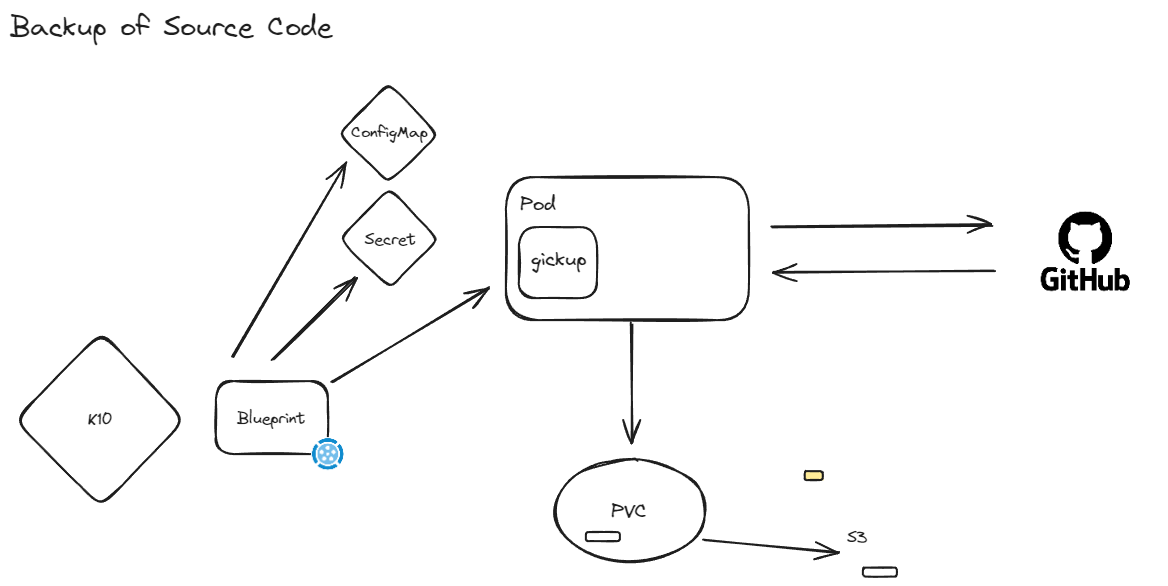
Deployment
You will need:
- A Kubernetes Cluster
- A GitHub Token (I am using GitHub as my example) this is to be placed in your gickup-secret.yaml.
- Details for the configmap (see below for what is needed)
- Kasten will also need to be deployed on your Kubernetes cluster
First up we have our deployment,
apiVersion: apps/v1
kind: Deployment
metadata:
name: gickup-deployment
spec:
replicas: 1
selector:
matchLabels:
app: gickup
template:
metadata:
labels:
app: gickup
spec:
containers:
- name: gickup
image: michaelcade1/kanister-gickup:0.1
env:
- name: GITHUB_TOKEN
valueFrom:
secretKeyRef:
name: gickup-secret
key: github-token
volumeMounts:
- name: config-volume
mountPath: /config
readOnly: true
- name: backup-volume
mountPath: /backups
resources:
requests:
memory: "64Mi"
cpu: "50m"
limits:
memory: "128Mi"
cpu: "100m"
volumes:
- name: config-volume
configMap:
name: gickup-config
- name: backup-volume
persistentVolumeClaim:
claimName: gickup-pvc
Next is the configmap, in which you will need to add your user, included repos (if none are added then all repos will be collected), as well as defining how many copies you would like to keep within the Persistent Volume Claim and a logging option as well.
apiVersion: v1
kind: ConfigMap
metadata:
name: gickup-config
data:
conf.yml: |
source:
github:
- token: GITHUB_TOKEN
user: <add your github username>
include:
- <add specific repo names here>
wiki: true
issues: true
destination:
local:
- path: /backups
structured: true
zip: true
keep: 5
bare: true
lfs: true
log: # optional
timeformat: 2006-01-02 15:04:05 # you can use a custom time format, use https://yourbasic.org/golang/format-parse-string-time-date-example/ to check how date formats work in go
file-logging: # optional
dir: /backups/logs # directory to log into
file: gickup.log # file to log into
maxage: 7 # keep logs for 7 days
For this iteration we are still using a Deployment and PVC scenario and later on we will try and enhance this so that you do not need to have the pod running continously using built-in Kanister functions to achieve this.
apiVersion: v1
kind: PersistentVolume
metadata:
name: gickup-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
hostPath:
path: /path/to/host/directory
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: gickup-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
Finally, create a secret, to store your github token.
apiVersion: v1
kind: Secret
metadata:
name: gickup-secret
type: Opaque
data:
github-token:<add token here>
Once you have those files with your details you can then deploy this to your cluster. For my testing I used a dedicated namespace called gickup for ease of management and also to be able to annotate later when it comes to the Kanister blueprint.
The Blueprint
Now with the above there is a native option within the Gickup configuration to use cron jobs, however this will only provide the capability to send our backups to the PVC. With the blueprint, we now have the ability to send those backups off-cluster to an immutable S3 or Object Storage location profile using Kasten.
The gickup-blueprint-k10 file is shown below,
add this to your cluster with kubectl apply -f gickup-blueprint.yaml -n kasten-io
Then annotate the gickup namespace with the following command, kubectl --namespace=gickup annotate deployment/gickup-deployment kanister.kasten.io/blueprint=gickup-blueprint
apiVersion: cr.kanister.io/v1alpha1
kind: Blueprint
metadata:
name: gickup-blueprint
actions:
backup:
outputArtifacts:
ghBackup:
# Capture the kopia snapshot information for subsequent actions
# The information includes the kopia snapshot ID which is essential for restore and delete to succeed
# `kopiaOutput` is the name provided to kando using `--output-name` flag
kopiaSnapshot: ""
phases:
- func: KubeExec
name: backupToStore
args:
namespace: ""
pod: ""
container: "gickup"
command:
- bash
- -o
- errexit
- -o
- pipefail
- -c
- |
gickup /config/conf.yml
kando location push --profile '' --path "/gickup-backups" --output-name "kopiaOutput" /backups
restore:
- func: KubeExec
name: restoreFromStore
args:
namespace: ""
pod: ""
container: "gickup"
command:
- bash
- -o
- errexit
- -o
- pipefail
- -c
- |
kopia_snap=''
kando location pull --profile '' --path "/backups" --kopia-snapshot "${kopia_snap}" <TARGET PATH>
Create the Backup Policy and Location Profile
To finish this off you will need a location profile configured within Kasten and then create a policy that uses the gickup namespace.
Conclusion
Much like any SaaS solution, we need to be mindful of protecting our source code hosted “in the cloud.” All too often, people and organizations alike place blind faith in SaaS providers that their data is being backed up and protected, however that often is very much not the case.






{kind=link}