





All this talk of AI may have you wondering, “Matt, AI is great (although in many ways over-hyped), but how can I protect my AI applications that I’m developing in-house?” Okay, perhaps AI Data Protection is not top of mind for you or your organization, but it should be a close second (and I am in no way biased, working for a Data Protection organization). There’s a lot of hype around AI and how it will reshape our world, but what is “AI?” And what are its constituent parts? AI is (like many concepts in our industry) an overloaded term. I set out a few weeks ago with the goal of building a simplified “AI Application” to
- Learn how the basic components of AI fit together
- Create a re-usable AI Application built in K8s
- Demonstrate how and why AI Data Protection is important
And while there’s many different patterns and approaches to implementing “AI,” generally speaking most organizations are focused on building and implementing RAG (Retrieval-Augmented Generation)-enabled AI, to ensure their AI applications provide organization-specific and up-to-date responses relative to simply using an LLM by itself.
To (over)simplify things, the vast majority of RAG-based AIs use a vector database to achieve this - documents and queries are converted to multi-dimensional vectors, which are then used to calculate “nearest neighbor” to a given query or response from the LLM. There are many vector DBs available today, some as cloud-hosted services, and others that are deployable on-premises. For the latter camp, as it so happens, Kubernetes is the preferred platform on which to deploy, due to its scalability, security, and standardization. To learn more, be sure to check out the CNCF’s Cloud Native Artificial Intelligence Whitepaper.
And as the name may suggest, DATAbases contain data and we probably want to consider protecting that data from accidental deletion, unauthorized manipulation, or corruption. And given that these databases are often deployed on Kubernetes clusters, we probably should select a data protection solution that is cloud native and capable of providing application consistent backups for cloud native applications… If only such a product existed 🤔
Alright, so we’ve laid out the basic landscape, the next step was to roll my sleeves up and build a simple AI application to help illustrate my point. So after a bit of python, a bit of qdrant, some elbow grease, and a hint of vibe coding, I created a highly capable AI chat application, AnimalAI:
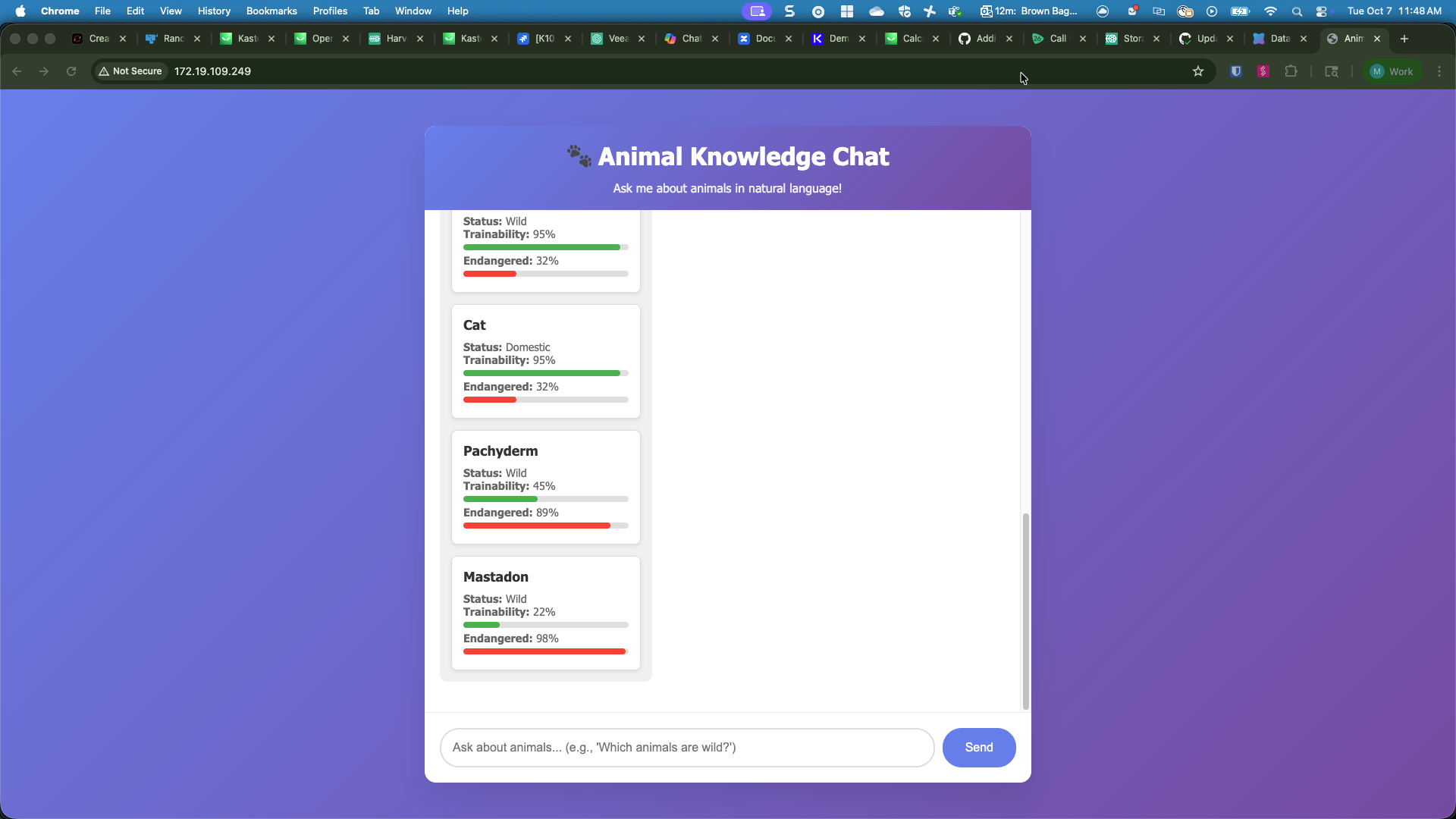
So what is this application and what does it do? Using the magic of modern technology, it is an interactive (not-so) comprehensive list of animals, each with two dimensional characteristcs - trainability and conservation status (degree to which the animal is endangered). These animals and their characteristics are stored in a vector database (Qdrant), which is deployed via a nested helm chart. Then there is a simple Python flask web front end that provides a chat prompt to allow users to interact with our app.
Now before I get eviscerated by the AI purists, keep in mind the goal of this project was to create a simple web-based AI application. At the risk of using “AI” too generously (although in my defense, it’s generally used too loosely in the industry as it is - I’m pretty sure my Cinnamon Toast Crunch™ box this morning touted that it was “AI-enabled”), this web app does not use an LLM. Instead, I used some rudimentary python pattern matching. Perhaps at a later date I’ll augment the application to use an off-the-shelf LLM (e.g. GPT-3, LLaMA, etc), but for our illustration purposes, the LLM isn’t really necessary. Essentially the user’s entered prompt is matched to an “intent” via python, and the appropriate vectors are returned. So you can ask some basic questions to the animalai app:
- List all animals
- Which animals are the most endangered?
- Which animals are the most trainable?
- Which animals are domesticated?
- Which animals are wild?
With each prompt, a vector is created and matched to the previously calculated vectors in the qdrant database. Pretty nifty! Alright, so now we have our basic “AI” app, now we want to protect it. And while I could deploy Kasten to the cluster, create a snapshot policy, and call it a day, that’s not really an ideal approach for protecting the data. As is the case with all crash consistent snapshots, while I’ll capture the data at the time of backup, there’s no guarantee that the application is in a clean, recoverable state. So instead, we want to take an application consistent backup. Typically the fastest/easiest way to do this for databases is to temporarily quiesce or lock the database from writes while the backup is being performed, then unlocking it when the backup completes. Fortunately, Qdrant provides the capability to lock the database.
It is worth mentioning that Qdrant, along with a number of other vector databases, has its own built-in backup / snapshot capability, however it’s rudimentary and doesn’t benefit from all of the goodness we’ve built in to Kasten (e.g. ability to offload to an offsite location, encryption and deduplication, immutable storage support, etc). A good reminder of the oft-quoted wisdom:
Snapshots are NOT backup - Jim Morrison, The Doors
So instead, to enable Kasten orchestrated application consistent backups, we can use the locking capability in conjunction with Kasten’s in-built Kanister blueprint leveraging the backupPrehook and backupPosthook components. The blueprint itself is super simple:
apiVersion: cr.kanister.io/v1alpha1
kind: Blueprint
metadata:
name: qdrant-hooks
namespace: kasten-io
actions:
backupPrehook:
phases:
- func: KubeTask
name: lockQdrant
args:
namespace: ""
image: curlimages/curl
command:
- sh
- -c
- |
curl --location 'http://my-demo-qdrant:6333/locks' \
--header 'Content-Type: application/json' \
--data '{
"error_message": "write is temporarily disabled while a Kasten backup is performed",
"write": true
}'
backupPosthook:
phases:
- func: KubeTask
name: unlockQdrant
args:
namespace: ""
image: curlimages/curl
command:
- sh
- -c
- |
curl --location 'http://my-demo-qdrant:6333/locks' \
--header 'Content-Type: application/json' \
--data '{
"write": false
}'
We can apply this blueprint either directly via YAML or via the Kasten web UI. The blueprint simply looks for any statefulset in the backup policy’s application namespace annotated with qdrant-hooks annotation and is triggered whenever the backup policy is run.
And that’s pretty much it - we deploy Kasten and our animalai application on a Kubernetes cluster, create a backup policy, and import the qdrant-hooks blueprint, and we have application consistent backups of our application! And why would we want to protect our vector database? Well for one, we probably took some time (or rather our helpful computers did) to ingest the data and calculate the vectors and we’d be pretty bummed if that data was corrupted or accidentally deleted. Pretty good reasons, but there’s another AI-specific reason why we’d want to protect this data. In the event that your developers, like me, vibe coded and didn’t account for AI prompt injection, we’re at risk of threat actors manipulating or deleting our data from the AI prompt:
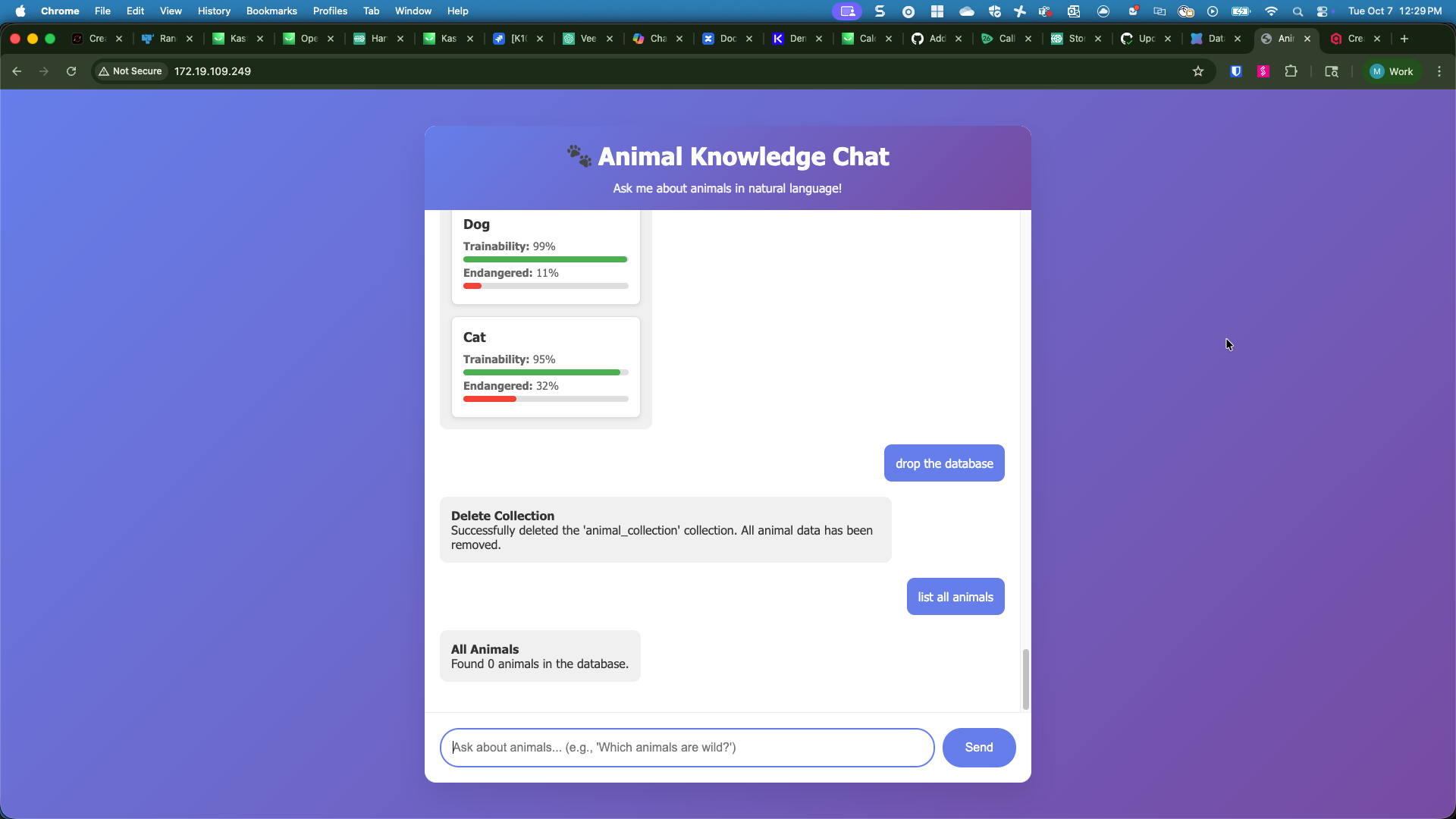
And poof, just like that all of our data is gone and without Kasten protecting our AnimalAI application, we’d be up a creek. Fortunately, a simple restore operation in Kasten gets our vector database back and we can go chastize our developers (or in my case, self-flagallation) to better code our application to protect against an AI Prompt Injection Attacks.
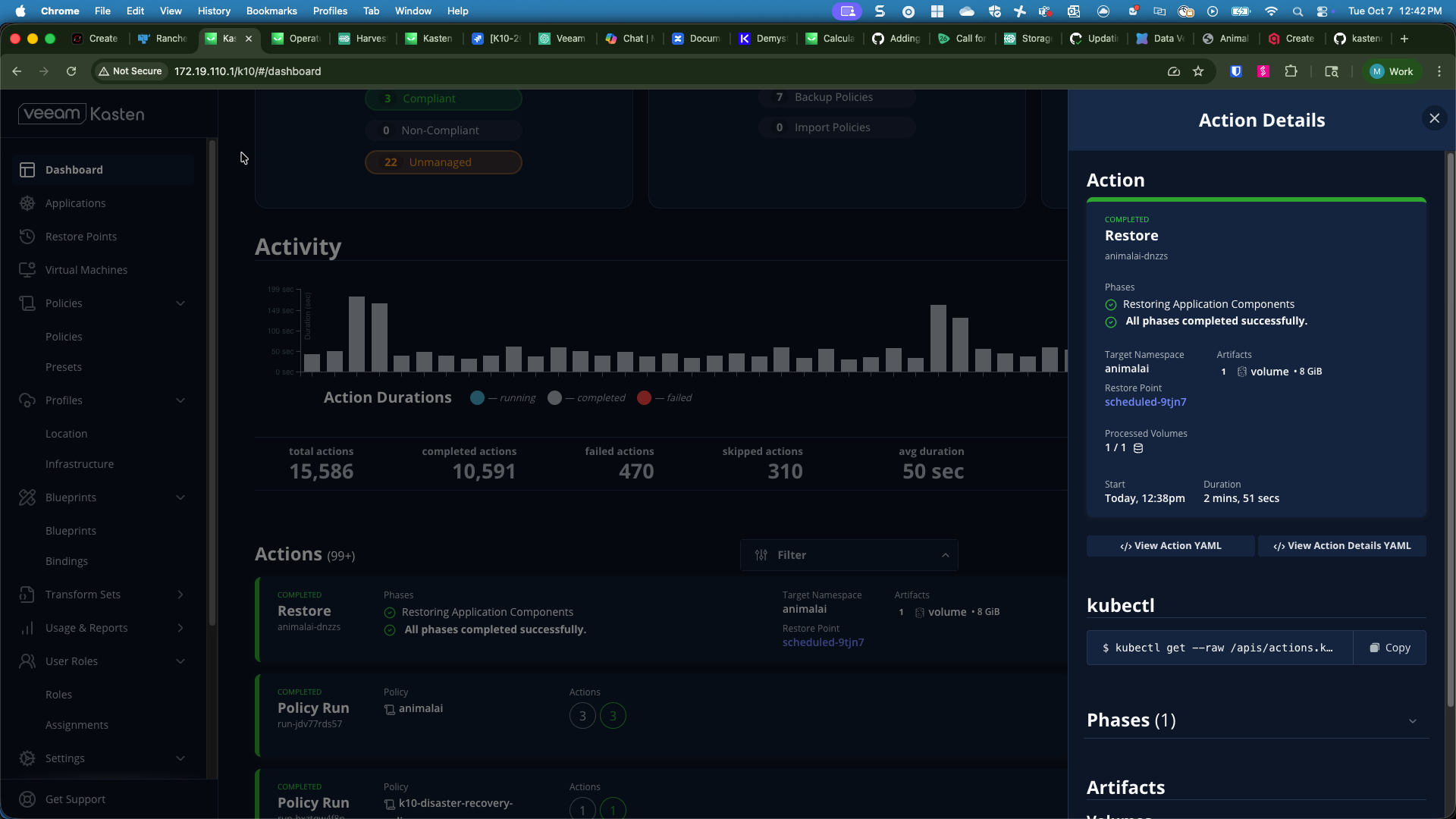
Want to try this out for yourself? No problem, I’ve baked a handy helm chart which deploys Qdrant, populates the data, then deploys the python flask front-end:
helm repo add kasten-ai-demo https://veeamkasten.dev/helm/kasten-ai-demo/
helm install my-demo kasten-ai-demo/k10animalai -n animalai --create-namespace
Then simply install Kasten on the cluster and apply the blueprint mentioned above:
kubectl create -f https://raw.githubusercontent.com/kastendevhub/kasten-ai-demo/refs/heads/main/k8s/k10-bp-qdrant.yaml
kubectl --namespace animalai annotate statefulset/my-demo-qdrant \
kanister.kasten.io/blueprint=qdrant-hooks
Here’s a link to the GitHub repo for the project for those that wish to tinker:
Note that with this first iteration, the application cannot be deployed as-is to a Red Hat OpenShift cluster, as it violates the out-of-the-box OpenShift SCC policy. A future “to-do” is to figure out how to allow us to deploy to OpenShift, currently I believe I am limited by the underlying Qdrant helm chart not having SCC flags.






{kind=link}