






Integrating Backups into your GitOps Pipeline
This post is going to uncover some of the realities that we face around companies adopting a GitOps model within their infrastructure and operational procedures. Ultimately GitOps is going to rely on Git as a source control system.
The industry definition can be found below:
GitOps is an operational framework based on DevOps practices, like continuous integration/continuous delivery (CI/CD) and version control, which automates infrastructure and manages software deployment.
Atlassian - Is GitOps the next big thing in DevOps?
My thoughts on GitOps
I may also refer to GitOps in this post as CI/CD, as it can be considered a predecessor to GitOps. My take is that perhaps you are not a software development house today so maybe CI “Continious Integration” is not something that crosses your mind, however CD (Continuous Delivery) will absolutely be something every single customer running some sort of software should be considering deploying their software the GitOps way.
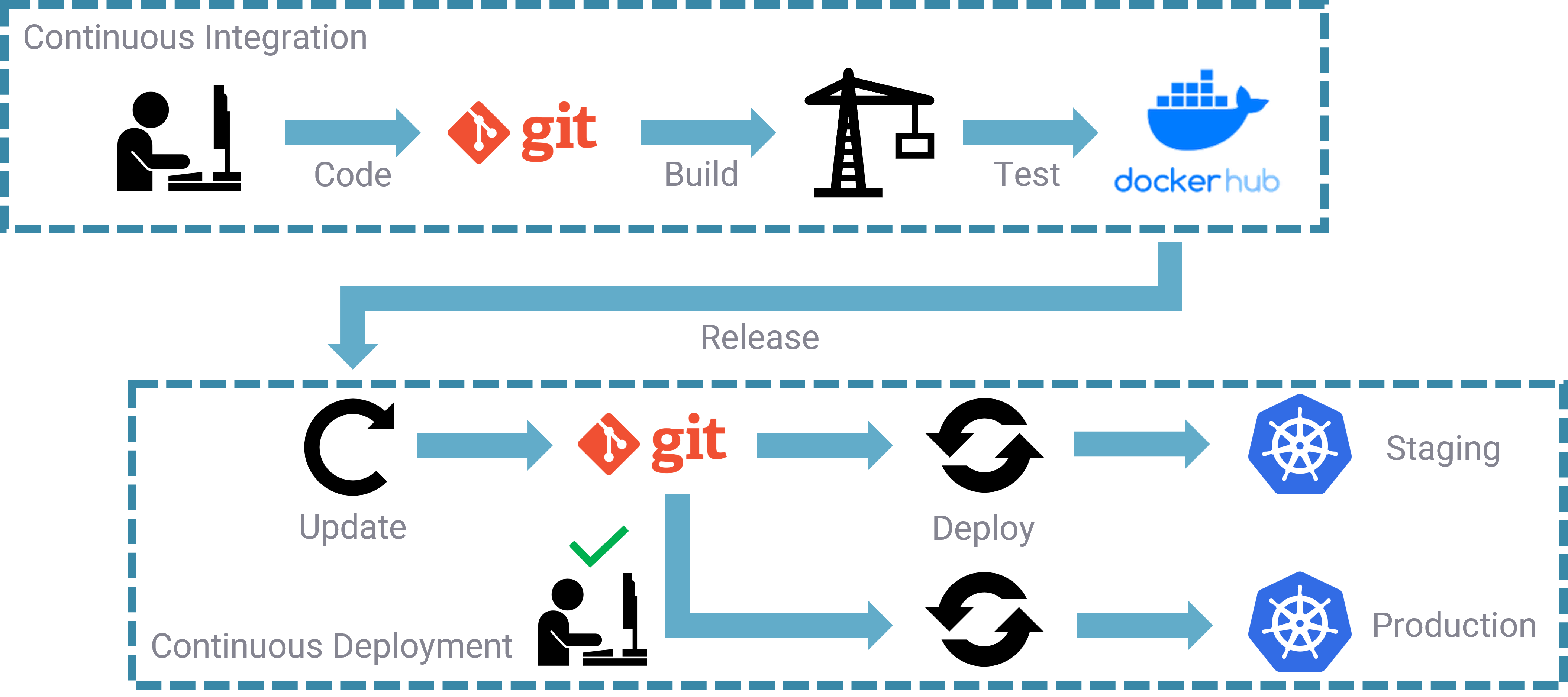
As software companies are speeding up the delivery of their software, where major releases can now occur within weeks rather than years, then GitOps is going to help you stay in control of these updates and provide you with a good way to keep track of those updates, but also provide a rollback workflow when bad things happen. Now if you only have one off-the-shelf software in your environment, maybe this is a stretch, but if you have lots of COTS (Commercial off-the-shelf software) then a GitOps approach is going to significantly help with management and control.
Introducing ArgoCD
In our example we are going to focus on ArgoCD and specifically Kubernetes as our platform to run our applications.
Argo CD is a Kubernetes-native continuous deployment (CD) tool. Unlike external CD tools that only enable push-based deployments, ArgoCD can pull updated code from Git repositories and deploy it directly to Kubernetes resources.
As you can see from the above description, ArgoCD is specifically built for Kubernetes and will pull updates from git based repositories but it also works with helm charts as well, which today is still the defacto package manager for Kubernetes.
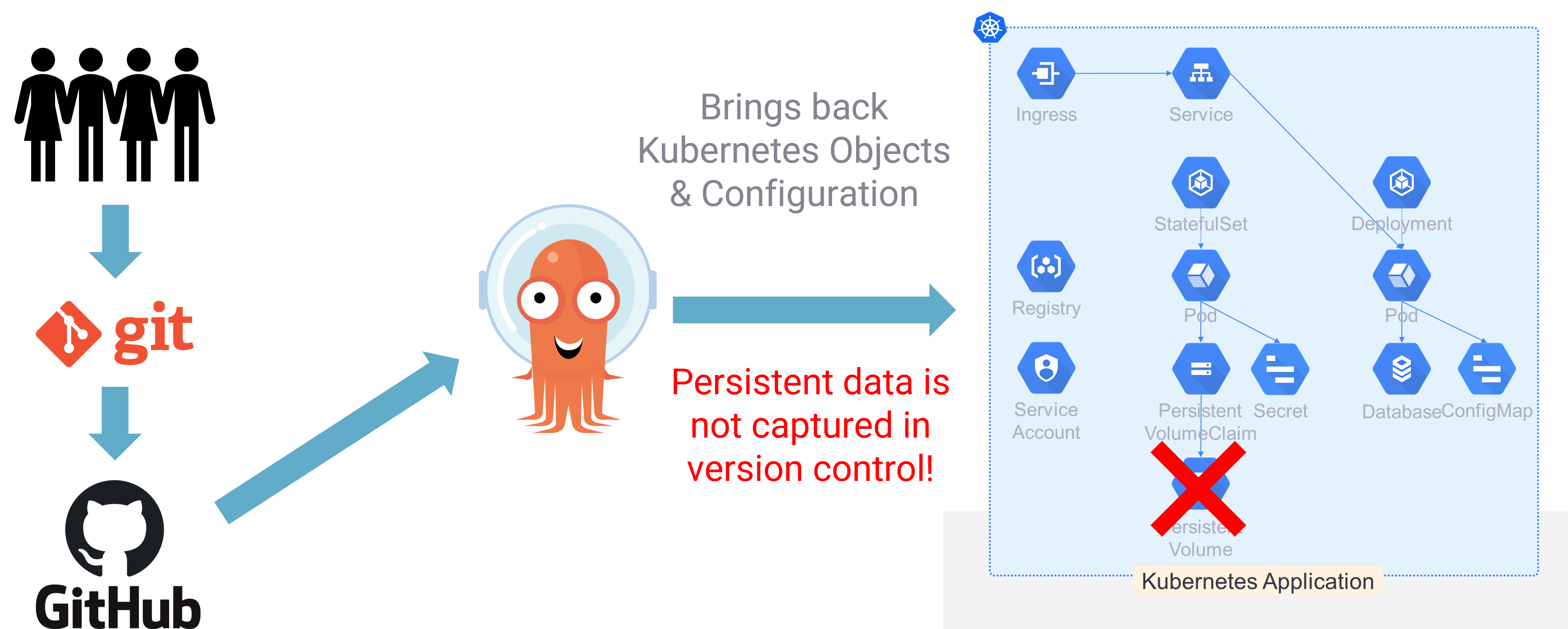
For the example in this post, we are going to be using a git-based repository with ArgoCD to get our Kubernetes application up and running. You can see what this application looks like below.
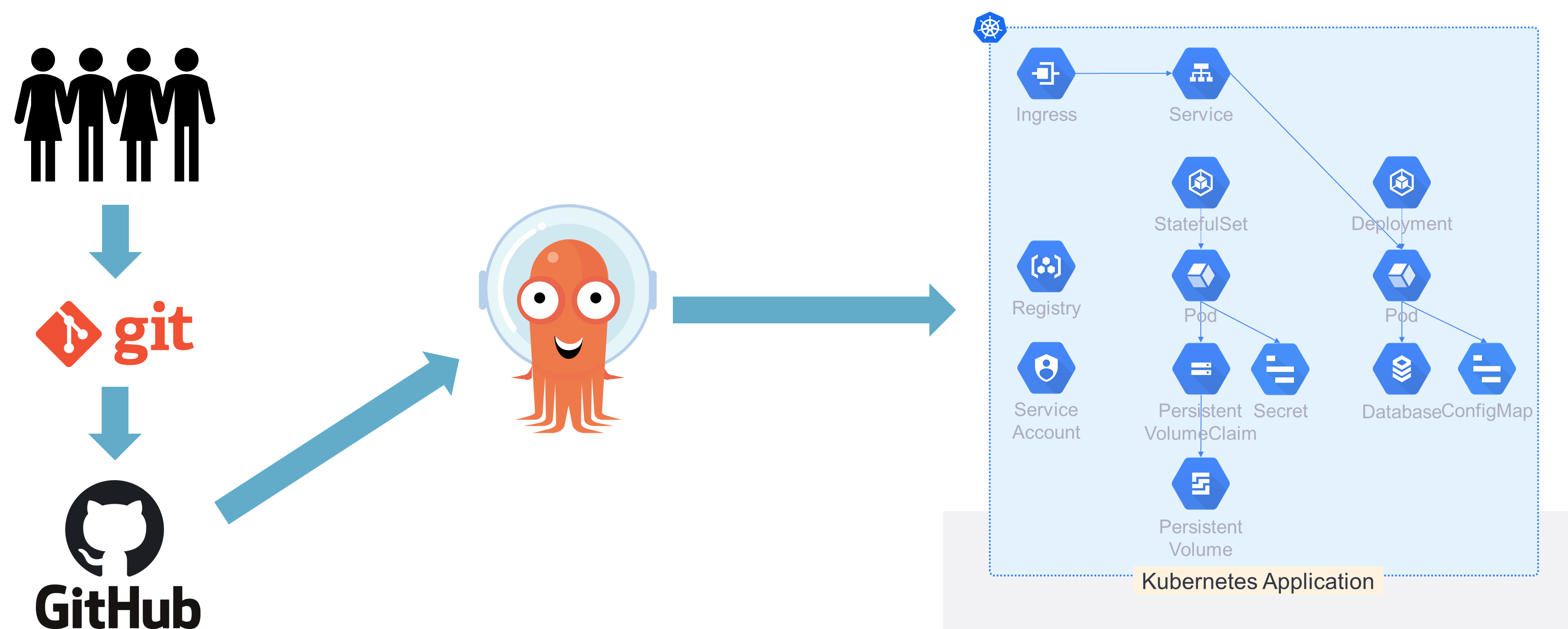
GitOps plus Data
Note that in the application architecture above, there is a persistent volume (PV). This persistent volume is attached to a MySQL database, which our application is using to store its mission-critical persistent data.
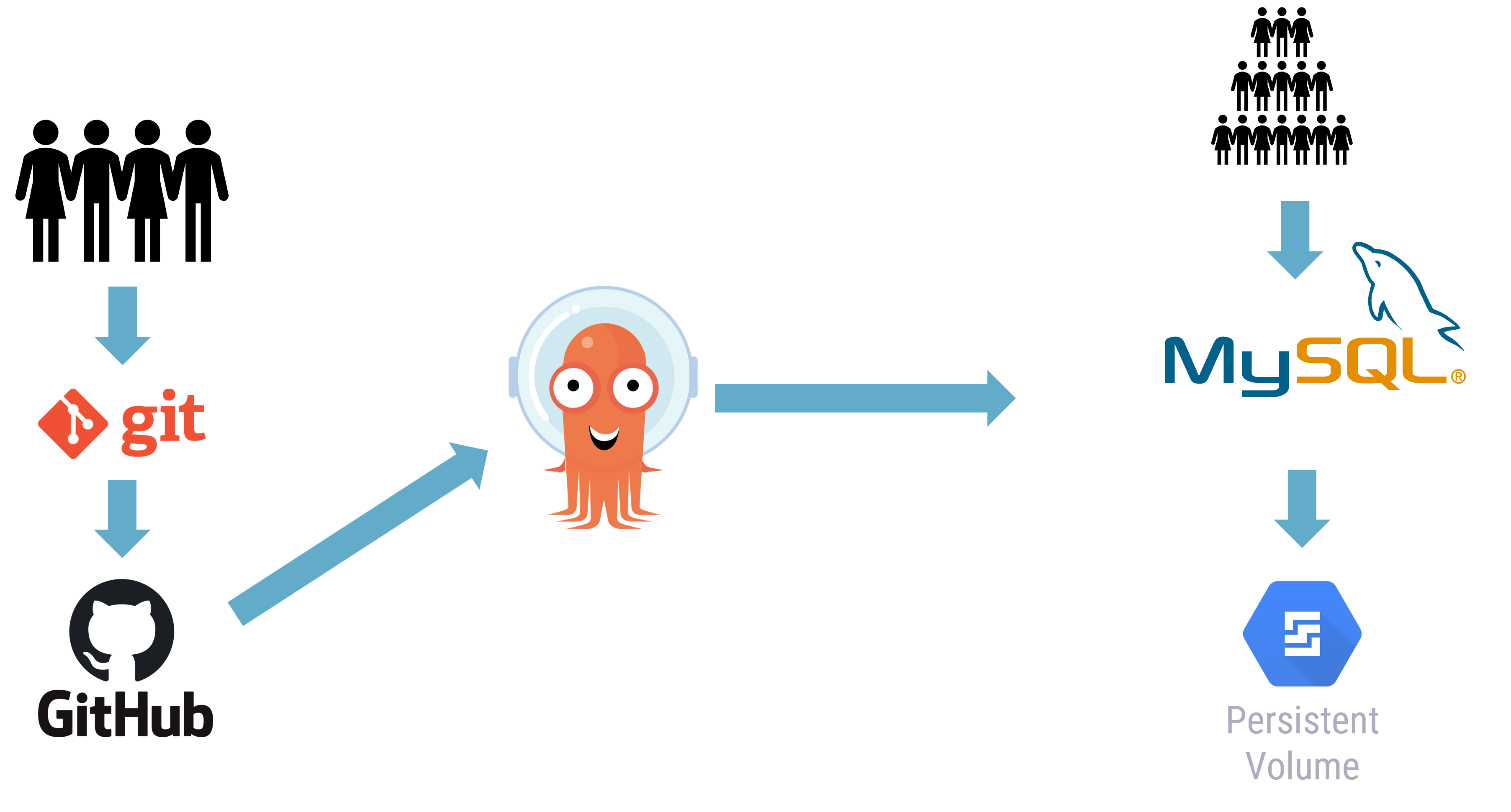
Whilst our git repository is great for our application’s Kubernetes objects, the application source code has no idea about the database and the contents of the database.
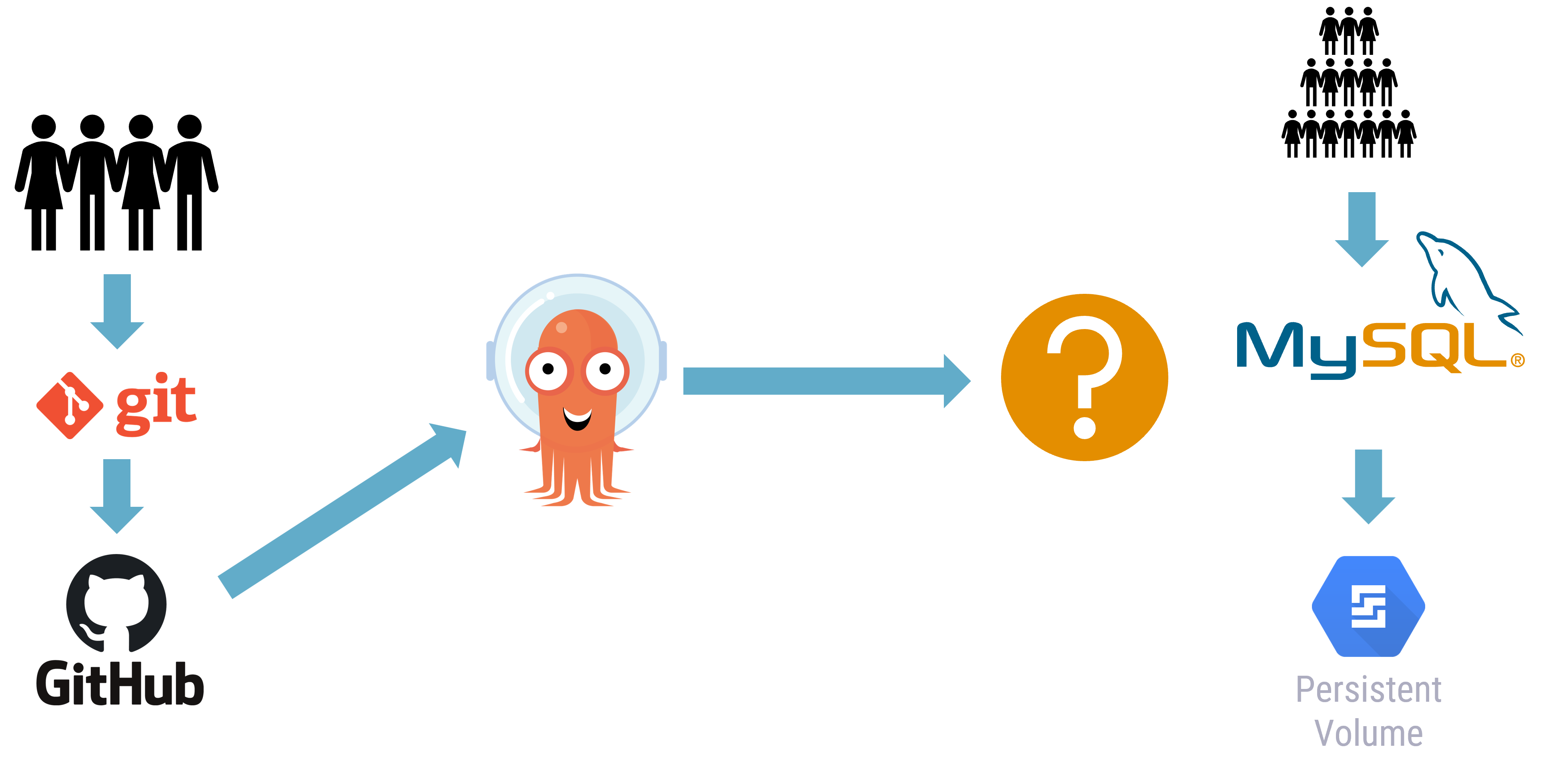
Thus, when it comes to our database and its important contents, version control systems alone will not store or protect this data.
And this isn’t just applicable to databases - any persistent data or volumes used by applications are not captured in version control.
Example: any stateful service, such as a relational database or NoSQL system
Requires the entire application stack including the data!
Data, and the dependencies of the stack on the data be discovered, tracked, and captured.
It is because of this that we must also protect our application data at specific times throughout its lifecycle and the best time for this to occur is prior to upgrading our application, as well as on an ongoing basis, to accoutn for other failure scenarios.
In the walkthrough demo below, we are going to do just that. We’ll take an application, which has a database element running alongside the application within the Kubernetes cluster and ensure we backup and store that data programatically. It’s worth noting that we can use the same approach for databases running externally such as with a managed database service like Amazon RDS or within a VM hosted on other infrastructure. In the case of external data services, we realize the benefit or protecting our application and database at the same point in time, rather than having to rely on potentially disjoint backup or data copy systems.
I have also ran through this just for the data service using Kanister.
Walkthrough Demo
Now we are going to play a little game, if you would like to follow along with this part of the post then you will find the steps here
In the example project referenced above, we use minikube, however it’s worth noting that in the most recent releases, the addons used in the project are not working with volumesnapshots or csi-hostpath-driver. In order to get these addons, we have to do so manually or you will have to find a different K8s cluster where persistent storage is provided via the CSI standard along with volumesnapshot capabilities.
The steps we will cover here will be:
- Deploy Kasten
- Deploy ArgoCD
- Set up Application via ArgoCD
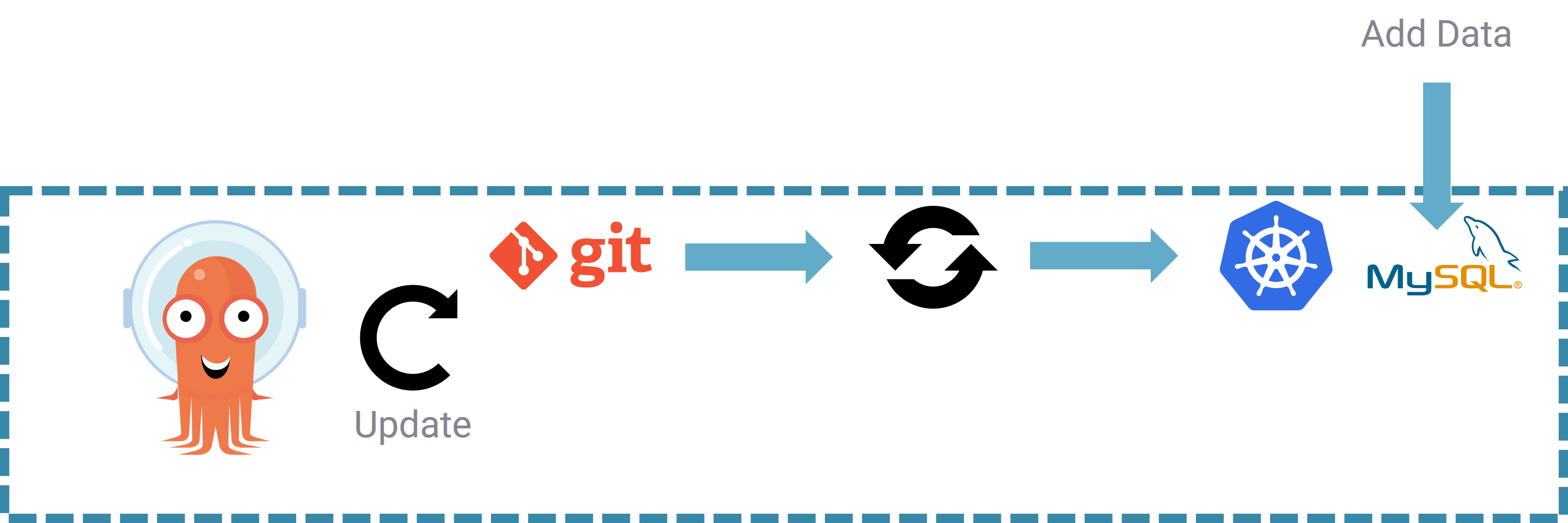
- Add some data
- Create ConfigMap to help manipulate data
- Simulate a Failure Scenario
- The Recovery
- Righting our wrongs
Ok lets get cooking.
I am going to assume at this point that you have a working Kubernetes cluster and you have validated pre-requisites using the Kasten primer and confirmed that your storage CSI is configured correctly and supports volumesnapshot capabilities.
On that cluster we are then going to deploy Kasten using a simple helm chart deployment.
Deploy ArgoCD
We will create a namespace for ArgoCD, deploy it, and set up a port-forward so we can access our ArgoCD instance.
In production, you’d likely want to use an ingress or LoadBalancer of some kind, but for our purposes, a port forward will suffice.
kubectl create namespace argocd
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
kubectl port-forward svc/argocd-server -n argocd 9090:443
The default username is admin and the password can be obtained with the following command:
kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d && echo
Set up Application via ArgoCD
First let us confirm that we do not have a namespace called mysql as this will be created within ArgoCD
We create a mysql app for sterilisation of animals in a pet clinic.
This app is deployed with Argo CD and is comprised of:
- A mysql deployment
- A PVC
- A secret
- A service to mysql
This is the URL required for ArgoCD - https://github.com/MichaelCade/argocd-kasten.git
We also use a pre-sync job (with corresponding service account (sa) and rolebinding) to backup the whole application with kasten prior to application sync.
At the first sync an empty restore point should be created because the backup action is always executed before the deployment of the app.

Add some data
Now let’s populate our database with some data. Because our application is used to track the sterilisation of animals (*remember to spay and neuter your pets, kids!), veterinarians (with a bit of knowlege of SQL) create the row of the animal they will operate.
It’s worth noting that we could build a simple web front end for this, as we wouldn’t expect our veterinarians to know SQL, or Kubernetes, but this example is just for illustration purposes.
mysql_pod=$(kubectl get po -n mysql -l app=mysql -o jsonpath='{.items[*].metadata.name}')
kubectl exec -ti $mysql_pod -n mysql -- bash
mysql --user=root --password=ultrasecurepassword
CREATE DATABASE test;
USE test;
CREATE TABLE pets (name VARCHAR(20), owner VARCHAR(20), species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);
INSERT INTO pets VALUES ('Puffball','Diane','hamster','f','2021-05-30',NULL);
INSERT INTO pets VALUES ('Sophie','Meg','giraffe','f','2021-05-30',NULL);
INSERT INTO pets VALUES ('Sam','Diane','snake','m','2021-05-30',NULL);
INSERT INTO pets VALUES ('Medor','Meg','dog','m','2021-05-30',NULL);
INSERT INTO pets VALUES ('Felix','Diane','cat','m','2021-05-30',NULL);
INSERT INTO pets VALUES ('Joe','Diane','crocodile','f','1984-05-30',NULL);
INSERT INTO pets VALUES ('Vanny','Veeam Vanguards','vulture','m','2019-05-30',NULL);
SELECT * FROM pets;
exit
exit
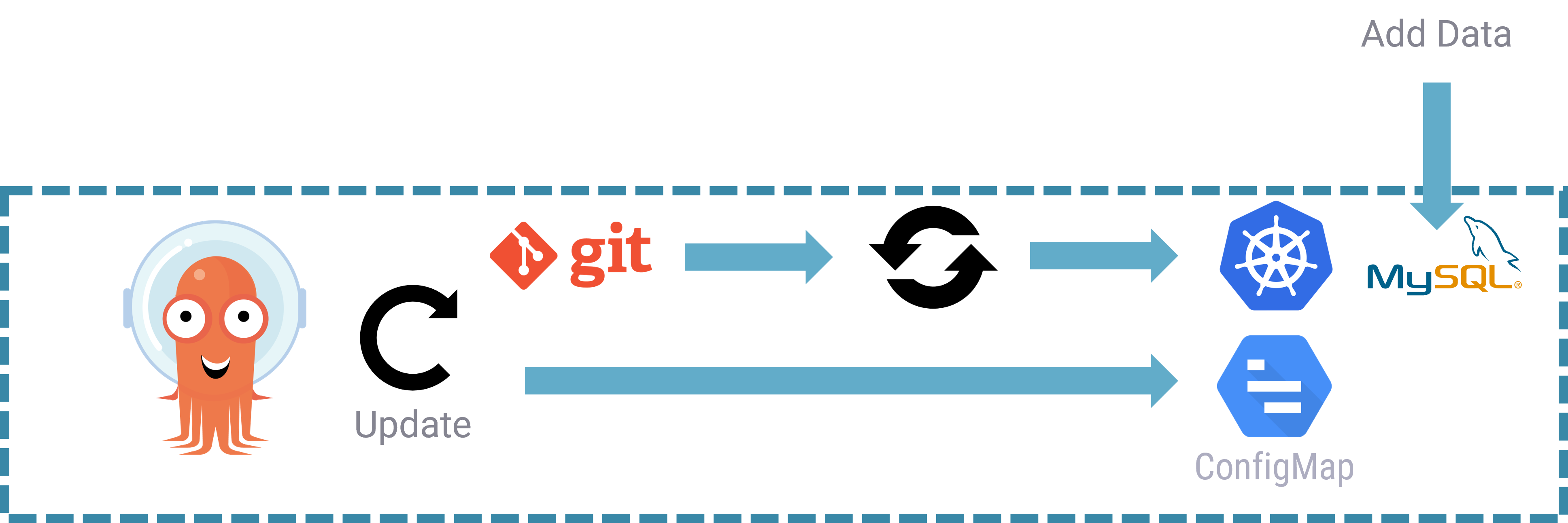
Create ConfigMap to help manipulate data
Next, we’ll create a kubernetes configmap that contains the list of species that won’t be eligible for sterilisation. This was decided based on the experience of this clinic, operation on this species are too expensive (or dangerous). We can see here a link between the configuration and the data. It’s very important that configuration (configmap) and data (our SQL data) are captured together.
cat <<EOF > forbidden-species-cm.yaml
apiVersion: v1
data:
species: "('crocodile','hamster')"
kind: ConfigMap
metadata:
name: forbidden-species
EOF
git add forbidden-species-cm.yaml
git commit -m "Adding forbidden species"
git push
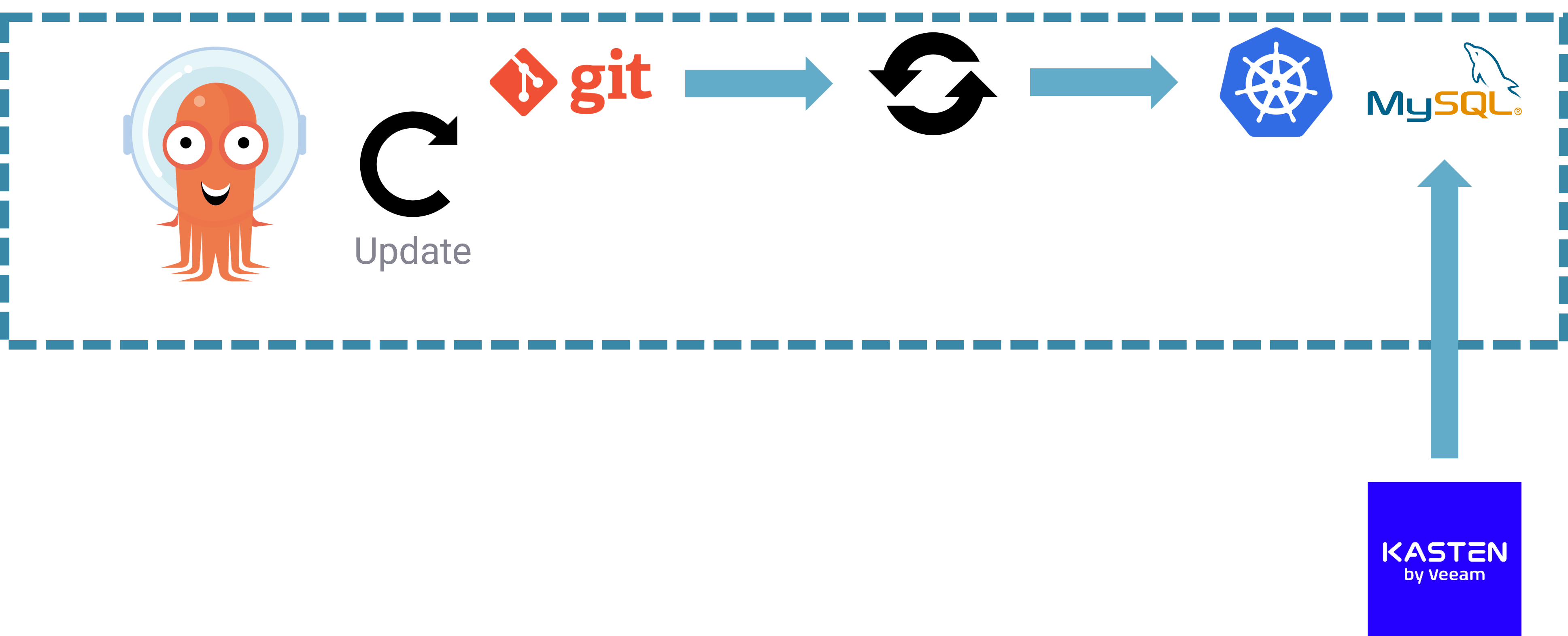
When deploying the app with ArgoCD, we can see that a second restore point has been created automatically.
Failure Scenario
At this stage of our walkthrough demo, we want to remove all the rows that have species specified in the list, specified within the configmap. To do so, we use a job that connects to the database and then deletes the rows.
Ah drats! We made a mistake in the code and we accidentally delete other rows.
Notice that we use the wave 2 argocd.argoproj.io/sync-wave: "2" to make sure this job is executed after the kasten job.
cat <<EOF > migration-data-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: migration-data-job
annotations:
argocd.argoproj.io/hook: PreSync
argocd.argoproj.io/sync-wave: "2"
spec:
template:
metadata:
creationTimestamp: null
spec:
containers:
- command:
- /bin/bash
- -c
- |
#!/bin/bash
# Oh no!! We forgot to add the "where species in ${SPECIES}" clause in the delete command :(
# This is why veterinarians shouldn't be running SQL!
# sad trumpet plays
mysql -h mysql -p\${MYSQL_ROOT_PASSWORD} -uroot -Bse "delete from test.pets"
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
key: mysql-root-password
name: mysql
- name: SPECIES
valueFrom:
configMapKeyRef:
name: forbidden-species
key: species
image: docker.io/bitnami/mysql:8.0.23-debian-10-r0
name: data-job
restartPolicy: Never
EOF
git add migration-data-job.yaml
git commit -m "migrate the data to remove the forbidden species from the database, oh no I made a mistake, that will remove all the species !!"
git push
Let’s head on back to ArgoCD and sync again and see what damage it has done to our database.
mysql_pod=$(kubectl get po -n mysql -l app=mysql -o jsonpath='{.items[*].metadata.name}')
kubectl exec -ti $mysql_pod -n mysql -- bash
mysql --user=root --password=ultrasecurepassword
USE test;
SELECT * FROM pets;

The Recovery
At this stage we could roll back using ArgoCD to our previous version, prior to Phase 4, but you will notice that this just brings back our configuration and it is not going to bring back our data!
Fortunately we can use Kasten to restore the data using the restore point.
You will see from the above now when we check the database our data is gone! It was lucky that we have this presync enabled to take those backups prior to any code changes. We can now use that restore point to bring back our data.
Lets now take a look at the database state after recovery
mysql_pod=$(kubectl get po -n mysql -l app=mysql -o jsonpath='{.items[*].metadata.name}')
kubectl exec -ti $mysql_pod -n mysql -- bash
mysql --user=root --password=ultrasecurepassword
USE test;
SELECT * FROM pets;
Righting our wrongs
We have rectified our mistake in the code and would like to correctly implement this now into our application.
cat <<EOF > migration-data-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: migration-data-job
annotations:
argocd.argoproj.io/hook: PreSync
argocd.argoproj.io/sync-wave: "2"
spec:
template:
metadata:
creationTimestamp: null
spec:
containers:
- command:
- /bin/bash
- -c
- |
#!/bin/bash
# Oh no !! I forgot to the "where species in ${SPECIES}" clause in the delete command :(
mysql -h mysql -p\${MYSQL_ROOT_PASSWORD} -uroot -Bse "delete from test.pets where species in \${SPECIES}"
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
key: mysql-root-password
name: mysql
- name: SPECIES
valueFrom:
configMapKeyRef:
name: forbidden-species
key: species
image: docker.io/bitnami/mysql:8.0.23-debian-10-r0
name: data-job
restartPolicy: Never
EOF
git add migration-data-job.yaml
git commit -m "migrate the data to remove the forbidden species from the database, oh no I made a mistake, that will remove all the species !!"
git push
Lets now take a look at the database state and make sure we now have the desired outcome.
mysql_pod=$(kubectl get po -n mysql -l app=mysql -o jsonpath='{.items[*].metadata.name}')
kubectl exec -ti $mysql_pod -n mysql -- bash
mysql --user=root --password=ultrasecurepassword
USE test;
SELECT * FROM pets;
Phew! Because we implemented data protection alongside ArgoCD, we will not only have our desired data in our database, but also peace of mind that we have a way of recovering if this accident happens again.

This post was to highlight the importance of data within our applications, remember I also mentioned that this MySQL database or any other data service might also be external to the Kubernetes cluster, but the same issues may arise. We need to ensure we protect both our application configuration AND our application data, as our version control system is “unaware” of any data stored within a database.
And while this is a simple example, hopefully it helps illustrate the importance of data protection in our GitOps pipelines, to protect our applications and their data, should we experience an accidental deletion, a mistyped command, or worse still, a ransomware attack.







{kind=link}