






At the risk of beating a dead horse, it needs to be said that Snapshots are not Backups. Why do we so often hear this from backup vendors, infrastructure engineers, and solution architects? Is it because they’re all trying to hawk their softwares at us? Do they think it makes them sound more intellectual, clever, and enlightened?
After all, I’ve screwed up a VM before and was able to successfully restore from a VMware snapshot, isn’t that core function of a backup? What’s really the difference? Anyway, why would any of this matter for Kubernetes? What is the airpspeed velocity of an unladen swallow? All great questions! Let’s address them in this blog post and end with a practical example using a Kanister blueprint.
-
We often hear this from backup vendors, infrastructure engineers, and solution architects because they themselves have been burned before by relying on snapshots for backup, not having a backup, or having what they thought was a backup but when they attempted to restore from it, found the end result to be a crashing application or corrupt data. Some also say it to sound more intellectual, clever, and enlightened.
-
VM or storage snapshots can be an effective way to restore quickly, particularly during infrastructure build or in dev/test situations, or even for some production workloads that write little or no data or we don’t care about the actual data. But they’re limited in their capabilities, can often cause performance issues (a topic for another day, but if you’re interested, here’s another blog by a different author about how vSphere snapshots work), or when restored, applications may not be happy with the state of the data. This is because snapshots (even “crash consistent” ones) often don’t account for high R/W operations. Depending on how the snapshot it taken, an application may be in the midst of writing a bunch of data to disk, and if that disk isn’t temporarily “paused” (aka quiesced) prior to the snapshot, some data may get lost, corrupted, or turn into something else completely. Another key difference is snapshots are often not cataloged in the same way backups nor are they intended to be long-lived. So keeping a bunch of snapshots around may have unintended performance consequences. And while we often heavily rely on storage subsystems to perform snapshots for us (Kasten loves a good compliant CSI driver with VolumeSnapshot and Restore capabilities), they often need to be used in conjunction with other application-aware or logical backup capabilities to ensure all data is captured safely, correctly, and is restorable. Obviously, your mileage may vary (YMMV) depending on what storage you’re using and applications you’re running, but these are some (not all) of the reasons why snapshots are not the same thing as backups.
-
It matters for Kubernetes because we see a lot of persistent data written in-cluster (if you’ve every found yourself typing
pvcorstorageclassin YAML, you more than likely have persistent data in your K8s cluster), or at the very least, written elsewhere (e.g. Amazon RDS or Azure Cosmos). If we’re reading/writing off cluster (e.g. Managed Database service, or even something as simple as NFS), we can back up that data or infrastructure in it’s own bubble, but what about our K8s application that references that data? We probably want to make sure our application and database are backed up at the same time and/or in the same state so when we restore, the application behaves as it did at the time of backup. Otherwise you could have a very grumpy application, or worse yet, one that misbehaves. A lot of applications are basically like toddlers.
So we’ve answered all of those great questions earlier, but let’s see how we can quickly implement application consistent backups for an application deployed in Kubernetes. We’ll use one of our favorite applications, Pacman, because it illustrates our points clearly, it’s a simple app that’s easy to deploy, and it’s fun to play pacman.
For brevity, we’re going to assume that you have a Kubernetes cluster up and running with a StorageClass configured, bonus points if it’s a CSI Driver as well as a volumesnapshotclass that supports volumesnapshots and restore. Also we’ll assume you have helm installed on your local machine. We’re also going to assume that you’ve (smartly) already installed Kasten K10 into your cluster using the process defined in the Kasten Documentation.
First let’s deploy our application:
helm repo add pacman https://shuguet.github.io/pacman/
helm install pacman pacman/pacman -n pacman --create-namespace --set service.type=LoadBalancer
If all goes well, you should have pacman up and running in K8s in no time!
$ k get deploy -n pacman
NAME READY UP-TO-DATE AVAILABLE AGE
pacman 1/1 1 1 42d
pacman-mongodb 1/1 1 1 42d
Note we have two deployments in the pacman namespace - pacman and pacman-mongodb. Let’s play a quick game:
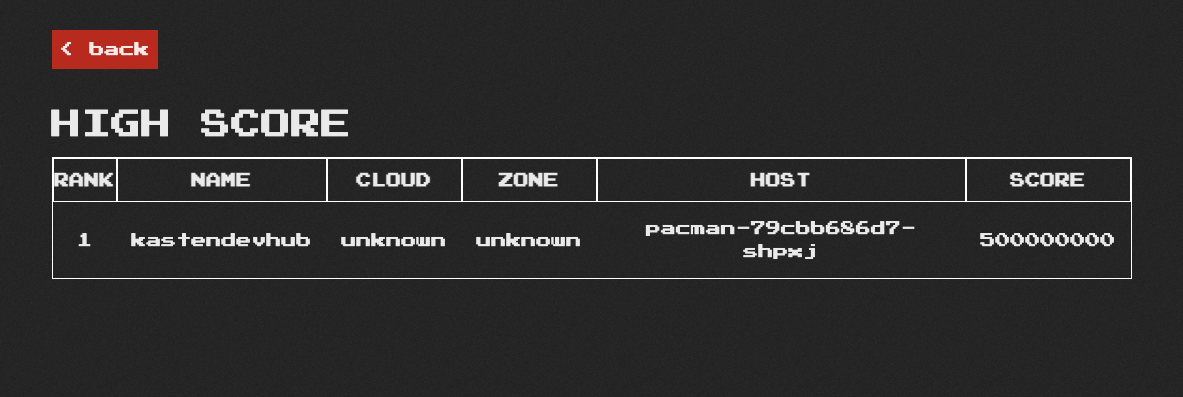
Wow, 500000000, I’m pretty great at pacman! So good in fact, I want to backup my score so if something happens, I can quickly recover it so I can brag next time I’m at a bar or there’s an attractive person within earshot. Let’s do so in the Kasten UI, at first just using the default Storage snapshot capabilities of our cluster’s storage:
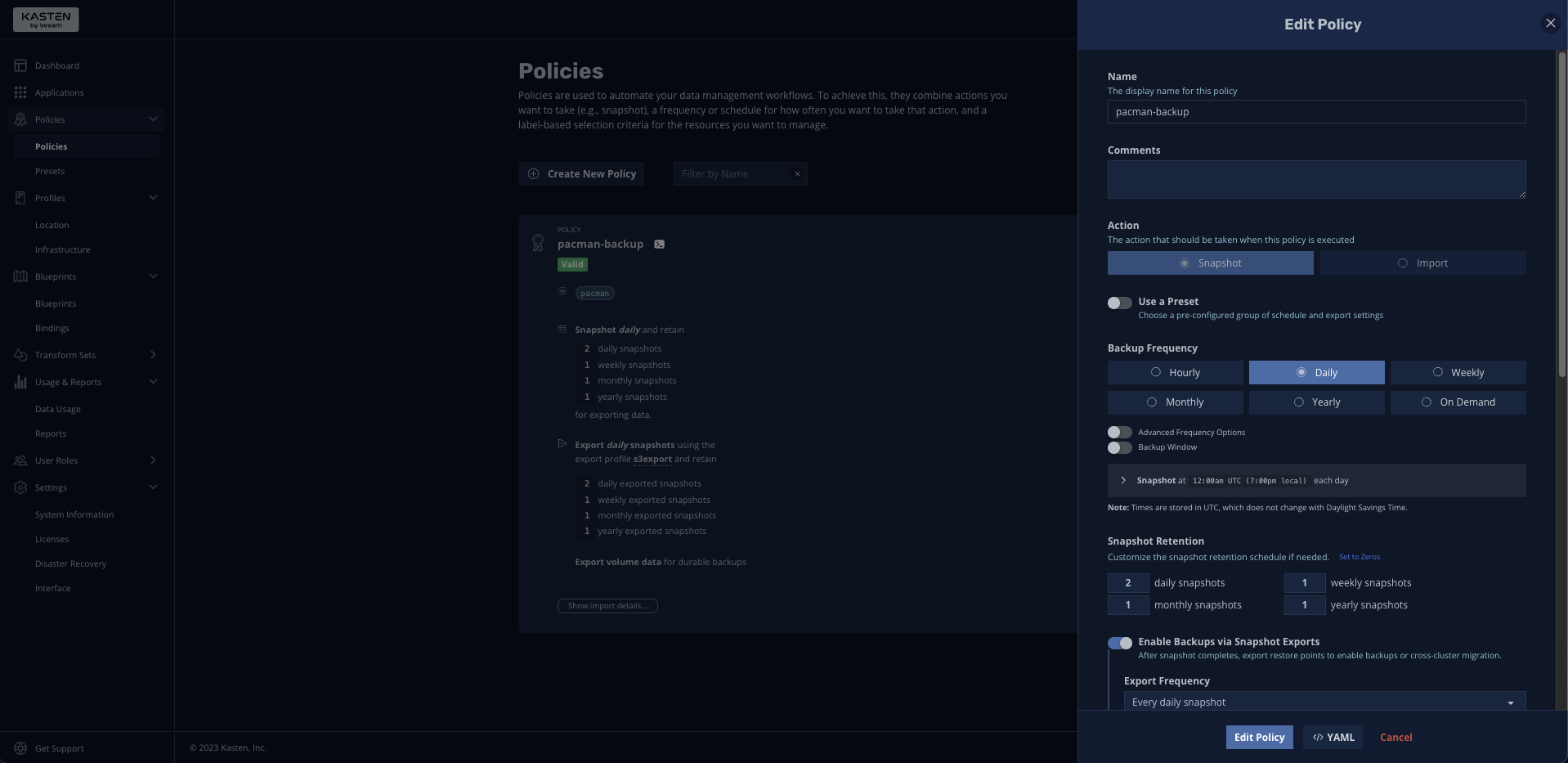
Pretty simple and easy! And for the most part, I’m in good shape. But what if lots of people are playing my pacman application simultaneously, in their naive, fruitless attempt to beat my incredible score and as a result, high scores are being written super frequently. The next time Kasten K10 performs a backup via snapshot, a score may be mid-write to the MongoDB, which means the write may start when the snapshot begins but doesn’t finish writing before it finishes… that would be bad news. Remember the angry toddler?
Fortunately Kasten has the capability to leverage a construct called Kanister Blueprints, which provides a standardized way to perform more advanced operations for application consistent and logical backups. This sounds scary, especially to an infrastructure guy, but fear not - there’s tons of examples and samples available to get you started.
And the good news is our Pacman application leverages an underlying Bitnami instance of MongoDB, so we can simply modify that example blueprint for our purposes. The YAML is below and we won’t run through what everything does, but there’s a few important lines to note to understand what’s going on:
cat <<EOF | k -n kasten-io apply -f -
apiVersion: cr.kanister.io/v1alpha1
kind: Blueprint
metadata:
name: mongo-hooks
actions:
backupPrehook:
phases:
- func: KubeExec
name: lockMongo
objects:
mongoDbSecret:
kind: Secret
name: 'pacman-mongodb'
namespace: '{{ .Deployment.Namespace }}'
args:
namespace: "{{ .Deployment.Namespace }}"
pod: "{{ index .Deployment.Pods 0 }}"
container: mongodb
command:
- bash
- -o
- errexit
- -o
- pipefail
- -c
- |
export MONGODB_ROOT_PASSWORD='{{ index .Phases.lockMongo.Secrets.mongoDbSecret.Data "mongodb-root-password" | toString }}'
mongosh --authenticationDatabase admin -u root -p "\${MONGODB_ROOT_PASSWORD}" --eval="db.fsyncLock()"
backupPosthook:
phases:
- func: KubeExec
name: unlockMongo
objects:
mongoDbSecret:
kind: Secret
name: 'pacman-mongodb'
namespace: '{{ .Deployment.Namespace }}'
args:
namespace: "{{ .Deployment.Namespace }}"
pod: "{{ index .Deployment.Pods 0 }}"
container: mongodb
command:
- bash
- -o
- errexit
- -o
- pipefail
- -c
- |
export MONGODB_ROOT_PASSWORD='{{ index .Phases.unlockMongo.Secrets.mongoDbSecret.Data "mongodb-root-password" | toString }}'
mongosh --authenticationDatabase admin -u root -p "\${MONGODB_ROOT_PASSWORD}" --eval="db.fsyncUnlock()"
EOF
Notice how we escape the dollar sign character in the above YAML. That’s because we’re applying the YAML directly from a BASH shell (see the cat <<EOF | k -n kasten-io apply -f - at the top of the file ), and if we didn’t do that, our local shell would be looking for a variable called MONGODB_ROOT_PASSWORD which probably doesn’t exist on our local machine and in the rare case that it did, it may not match what’s actually configured in our K8s cluster. Take a wild guess how I found this quirk when applying directly via shell…
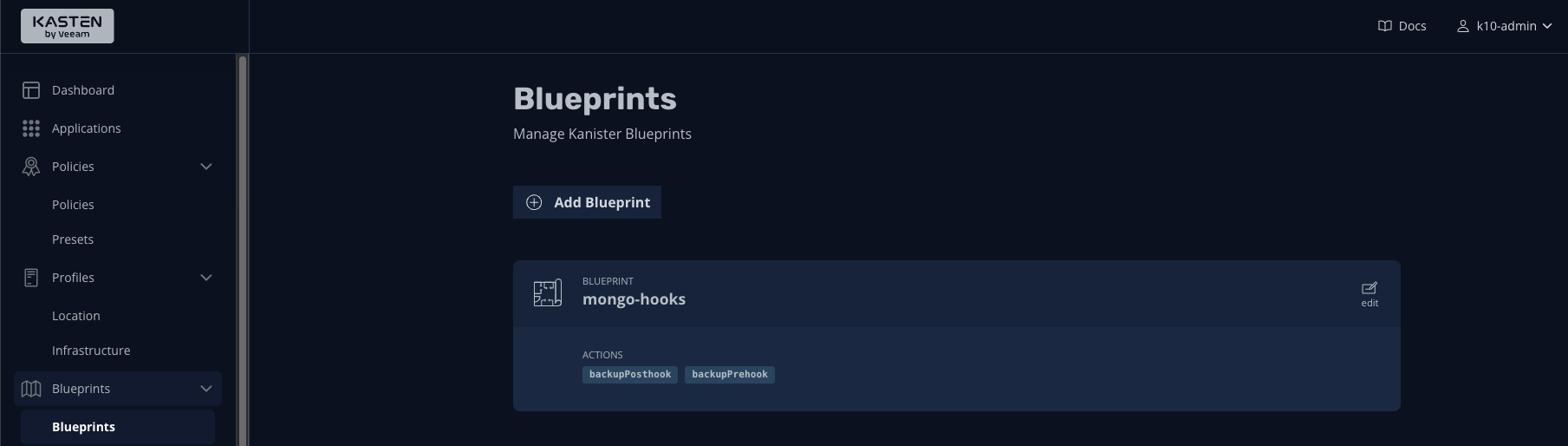
Note how we define a backupPreHook and backupPostHook section in the blueprint, which are operations we’re telling Kanister (and subsequently Kasten) to do before and after taking a snapshot. Then note further down in our command subsection for each:
Prehook
export MONGODB_ROOT_PASSWORD=''
mongosh --authenticationDatabase admin -u root -p "\${MONGODB_ROOT_PASSWORD}" --eval="db.fsyncLock()
Here we’re grabbing the root password for the mongo database which was defined higher up in our blueprint and exporting that as a string.
Then we run a simple mongosh command using that password, telling the database to pause operations using the db.fsyncLock() command.
Posthook
export MONGODB_ROOT_PASSWORD=''
mongosh --authenticationDatabase admin -u root -p "\${MONGODB_ROOT_PASSWORD}" --eval="db.fsyncUnlock()
Similarly, after the backup completes (Storage snapshot), we tell Mongo to unlock the database and resume operations.
Now we just need to annotate our pacman-mongodb deployment to map it to our newly created blueprint:
kubectl annotate deployment pacman-mongodb kanister.kasten.io/blueprint='mongo-hooks' -n pacman
And we’re good to go! Next time we perform a backup in Kasten K10, our blueprint will run, which will pause database operations, perform a storage snapshot, and resume database operations, and as a result, we’ll have a happy toddler application on our hands!
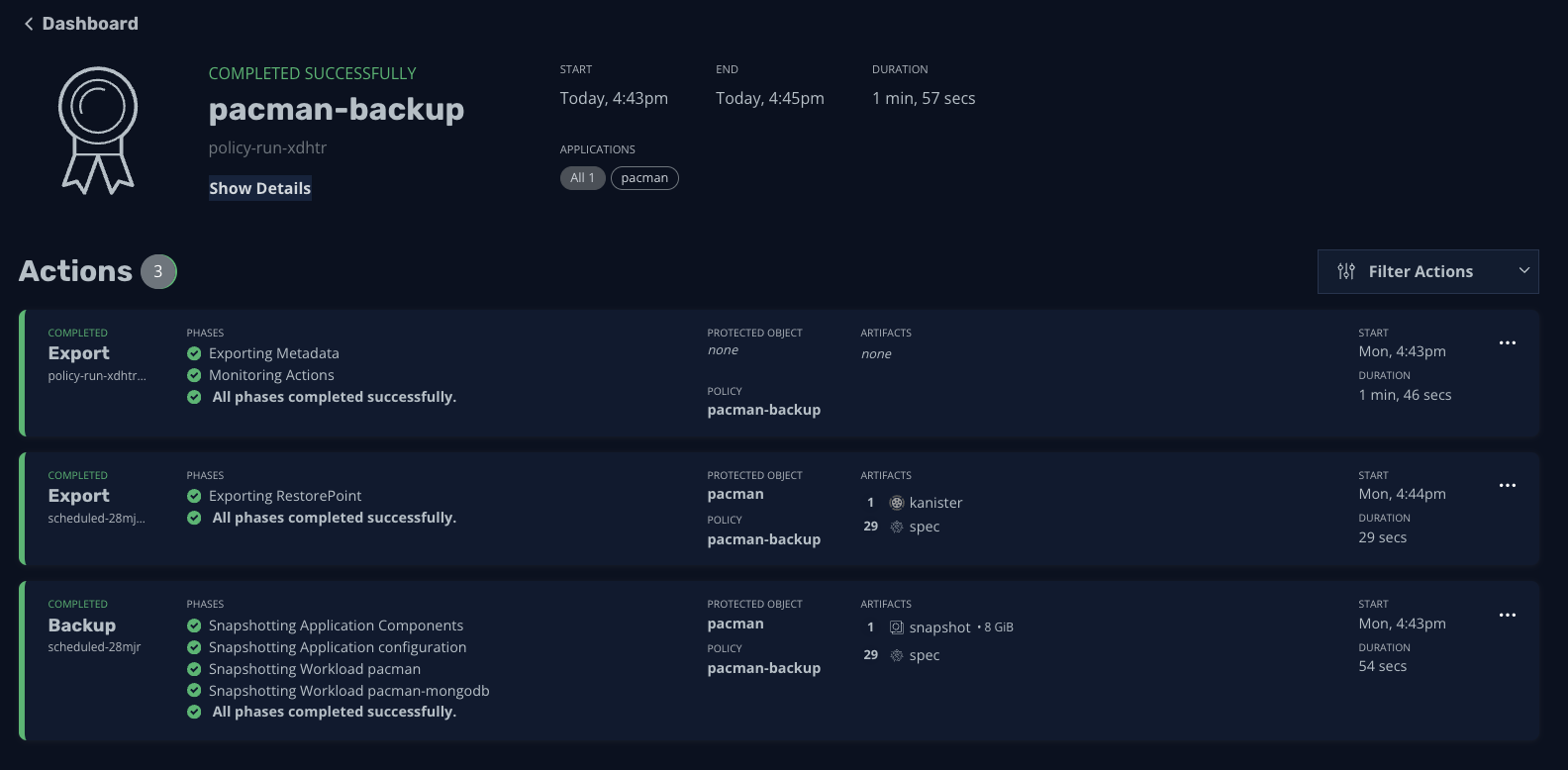
To learn more, checkout our interactive demos or videos on YouTube!




{kind=link}