






I know, I’ve been awfully quiet these past couple of months… TOO quiet, some might say. It’s primarily because I’ve been devoting my creative writing juices to our recently published Veeam Kasten and Red Hat OpenShift Virtualization Reference Architecture. rather than this blog.
Since the Broadcom acquisition of VMware earlier this year, we as an industry have seen some tumultous and exciting times. Many organizations, enterprises, and agencies are looking to ditch the “VTax” (to borrow a marketing quip from one of my old employers) in favor of a solution that:
- Won’t increase in price 3x-10x year over year
- Has Enterprise support
- Avoids vendor lock-in, whether it be hardware, or non-standardized ecosystems
- Accommodates the app modernization trajectory, where VMs and containerized applications are BOTH first-class citizens on the platform.
It just so happens that Red Hat OpenShift and Red Hat OpenShift Virtualization does just that! And while there is definitely a learning curve for those that are eschewing vSphere, in the long-term, it’s looking like a pretty smart move.
And while day 1 VM operations are handled well within the platform, we need to consider day 2 operations as well - namely backup and disaster recovery. And that’s where Veeam Kasten shines! Because we are deployed on-cluster, we can observe, protect, and recover all Red Hat OpenShift workloads - whether containers or VMs, or even workloads outside of the cluster. And the best part is we can treat the overall application as the atomic unit. What do I mean by that? Well let’s say you have an app today that is comprised of a containerized front-end, but with two database backends - perhaps one database is running on VM and the other using a cloud-hosted database service, like Amazon RDS. The beautiful thing about Kasten is we can protect the entire application via one backup policy, ensuring the overall application is protected in a crash consistent and application consistent manner.
Consider the diagram below:
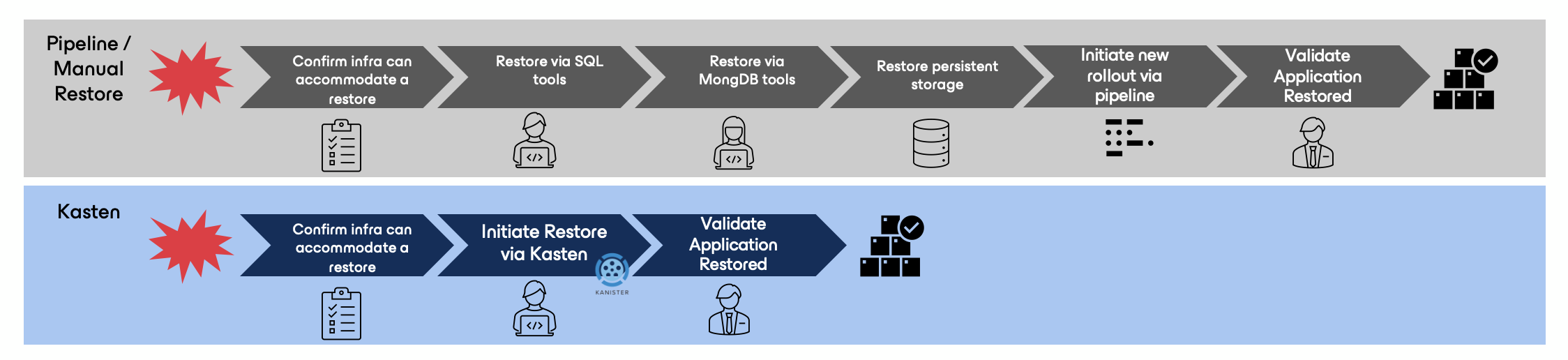
Using “traditional” or fragmented backup tools, we end up having to coordinate among our Database Admins, VM Admins, and Storage Admins, and ensure we trigger our pipeline run at the right time when all other dependencies are in place to allow for a “clean” recovery. And as the old Julia Child saying goes, “the more cooks in the kitchen, the less likely you are to meet your RTO targets and keep the business happy.”
So if you or your organization are considering the shift to OpenShift (see what I did there) and OpenShift Virtualization, be sure to download a copy of the reference architecture to get an idea as to how to deploy the solution in a robust and resilient way.
And if you prefer to consume your reference architectures in podcast form (it’s quickly replacing TrueCrime podcasts), checkout this AI-generated podcast on the matter.





{kind=link}