





Heads up, Suse has since released Harvester 1.3.1 which includes some required fixes to allow Kasten to support block mode exports, without the security workaround. Check out this newer post for more information!
Why Harvester and Why Should I Care?
With recent upheavels in the industry due to some major acquisitions, and questions about looming licensing renewals, it should come as no suprise that many enterprises, commercial and non-profit organizations, government agencies, and home labbers (and the family dog) are looking into their options for virtualization.
In a perfect world, we’d all just modernize our application workloads currently hosted within VMs into cloud native architectures, but that isn’t realistic - You can’t exactly satisfy your end-user-requirements all within a container (although I wouldn’t be surprised if someone has tried - project for another day is to deploy a FAT container with Gnome and try to redirect X to local machine). And some business critical apps simply don’t lend themselves to containerization - looking at you, COBOL, ForTran, and BASIC apps that keep our banking, healthcare, and core infrastructure running. So simply put, VMs aren’t going the way of the Dodo anytime soon. At the same time, we are seeing a large emeregence of cloud native apps running other business critical workloads (yay Kubernetes!).
So how do we help bridge the gap without complete IT sprawl and yet another set of consoles to manage all of our workloads? We have so many “single pane of glass” solutions, you can build a scale replica of the Louvre in pretty much any organization (Parisian inspiration because I am currently sitting in my hotel in Paris taking a break from KubeCon 2024).
The answer? KubeVirt! But what if I want an easy button with a packaged, lightweight solution, that doesn’t require a ton of installations and has a nice, easy-to-use interface? And what if I’m an enterprise/business/organization that needs support? There’s two options in this department, OCP-V (which we talked about in an earlier blog post) and Suse Harvester!
Rather than risk butchering a description of Harvester, I’ll plagerize the good folks at Suse’s description:
Harvester is a modern HCI solution built for bare metal servers using Linux, KVM, Kubernetes, KubeVirt, and Longhorn. It is free, flexible, and future-proof for running cloud-native and VM workloads in datacenter and at the edge.
And wowee, is it cool. So cool in fact that I ditched my previous homelab virtualization providers (I’ll not mention their names to protect the innocent… also Veeam has relationships with them and has backup offerings for each) and gone head first with Harvester.
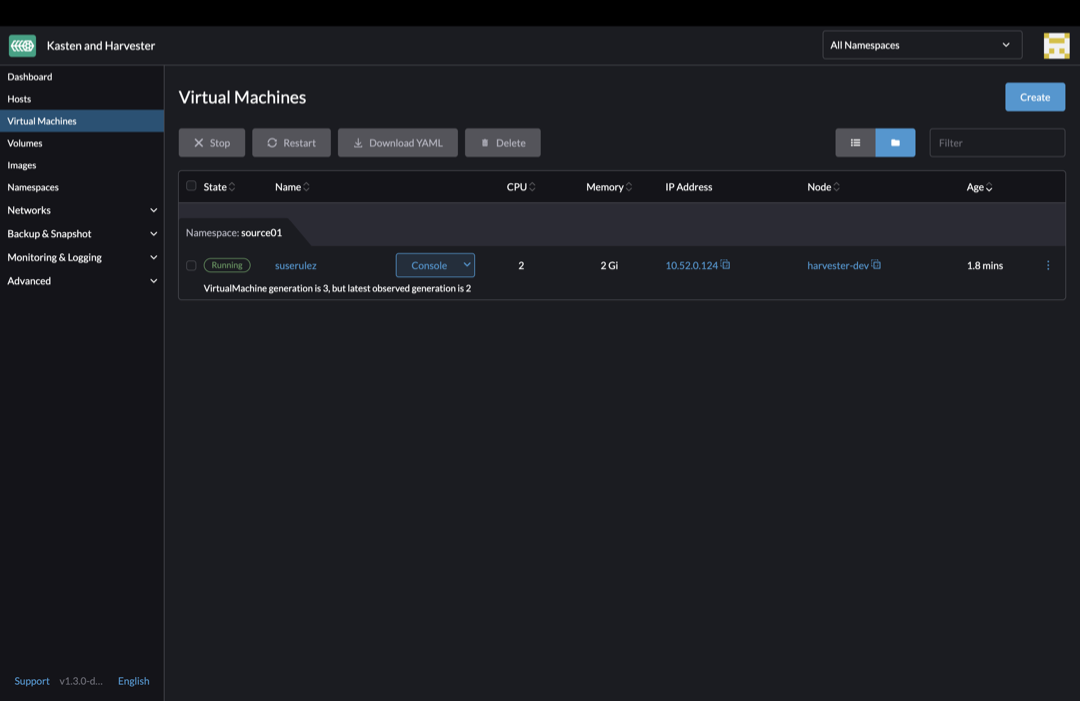
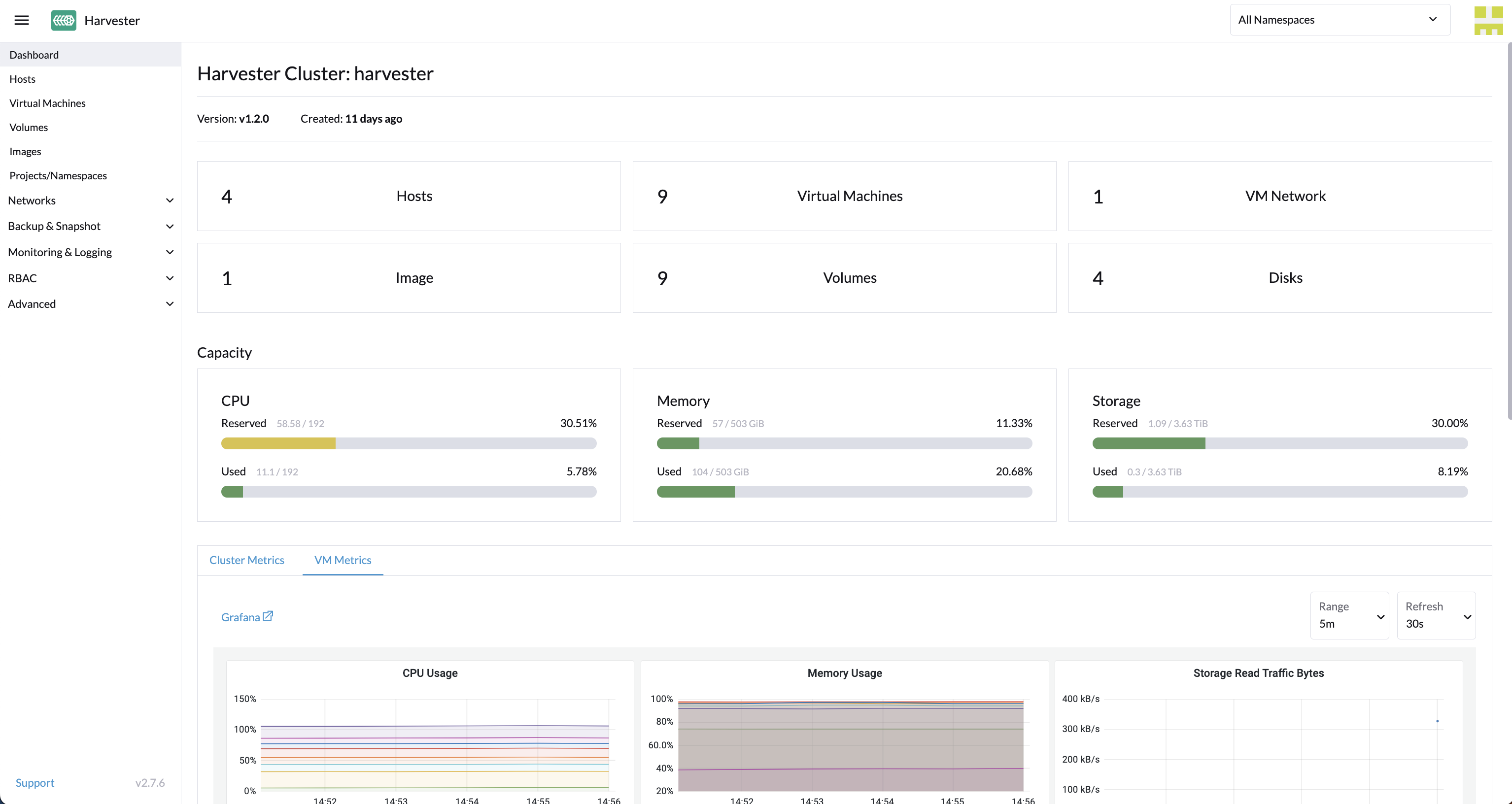
And while Harvester provides a lot of day 1 functionality that is needed for Virtual Machine management (e.g. images, cloning, power operations, mountint disks, etc), Longhorn backup leaves a bit more to be desired… Also factor in that you may have applications that are comprised of both VM and containerized components, you’ll want something that can protect all of these assets in one go. The answer? Kasten K10 by Veeam!
So without further adieue, let’s see how!
First, install Harvester on your hardware. Suse makes this dead simple, you boot their ISO image from USB, fill in a few options, and choose whether you want to create a new cluster or join an existing cluster, and within a few minutes, you’re pretty much ready to go. I won’t cover the steps here, but check out their very good Harvester Installation Documentation for the steps. Also worth nothing that it fully supports Air-Gapped environments, much like Kasten K10.
Next, connect to the cluster via KubeConfig… but HOW!? This requires a bit of detective work (or you can cheat like me and just ask the Suse Engineering team), but simply navigate to:
Support > Download KubeConfig in the UI to download the kubeconfig YAML file.
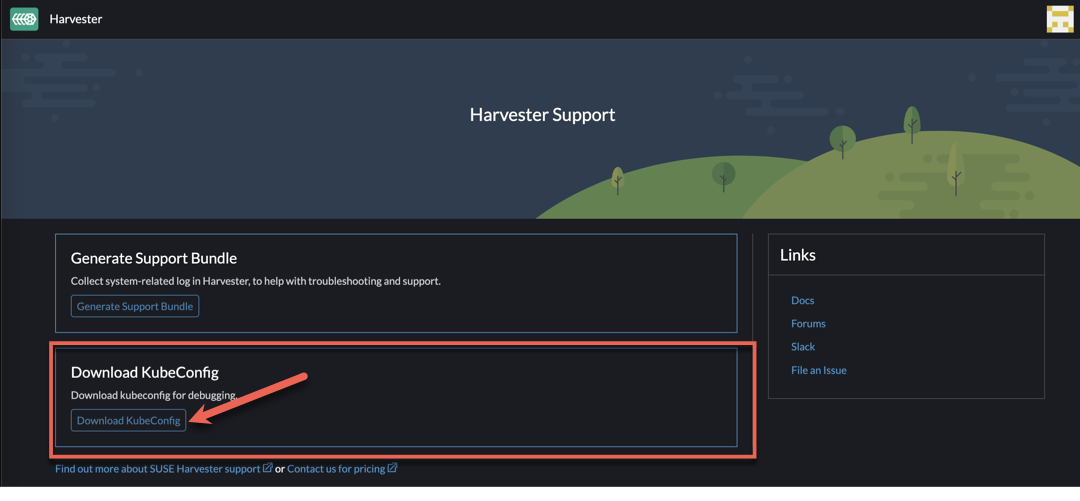
Next, if you are like me and have multiple K8s clusters in your kubectl config, merge the Harvester kubeconfig with the new Harvester kubeconfig file:
cp ~/.kube/config ~/.kube/config.bak
export KUBECONFIG=~/.kube/config:~/Downloads/local.yaml
kubectl config view --flatten > ~/.kube/config
kubectl config rename-context local harvester
kubectl config set-context harvester
Next, install Kasten via helm:
helm repo add kasten https://charts.kasten.io/
helm install k10 kasten/k10 --create-namespace -n kasten-io \
--set externalGateway.create=true \
--set auth.basicAuth.enabled=true \
--set auth.basicAuth.htpasswd='veeam:{SHA}jIRWj6Rhdep75BYFQaz0FSjZk60='
Note this will set the Kasten K10 user and password to: - User: veeam - Password: kasten
Wait a few minutes for Kasten to install. You can watch by running
kubectl get pods -n kasten-io --watch
Once all the pods are up, we’re mostly the way there! Next, let’s ensure we annotate the Harvester (Longhorn) snapshot class:
kubectl annotate volumesnapshotclass longhorn-snapshot k10.kasten.io/is-snapshot-class=true
Next, we need to annotate our harvester-longhorn snapshot class so that Kasten K10 knows it supports blockmode PVC exports:
kubectl annotate storageclass harvester-longhorn k10.kasten.io/sc-supports-block-mode-exports=true
Note this is an additional step on top of the typical Kasten deployment to support block mode exports, which is required for Kubevirt VMs.
Alright, now we’re cooking! So we’ve got K10 deployed and our volumesnapshotclasses and snapshotclass annotated, we’re ready to back up some VMs! Well not quite…
There’s a few quick things we need to take care of first:
- Out of the box, Harvester PVC security contexts sets disk permissions to 0,0 (root, root), which is no bueno from a security perspective - really we want it to be at most 0,6 (root, disk), to allow pods set with the security context of RunAsNonRoot (i.e. the Kasten block data mover pods) to still be able to read the disk so it can export a backup. The Harvester team is working on addressing this in their next release (hopefully in the next few weeks). Here is the relevant GitHub issue to track progress.
- Currently Harvester doesn’t have any built in way to expose a service (i.e. the Kasten UI) outside of the cluster. The easiest workaround today is to just port-forward from the Kasten gateway pod to your local machine.
kubectl port-forward -n kasten-io service/gateway 8000:80Once done, you can access the Kasten dashboard by opening a browser and navigating to http://localhost:8000/k10/#. A slightly more elegant solution is to deploy an nginx reverse proxy on a VM within harvester to access the Kasten dashboard.
- While Harvester is mostly pure kubevirt, it does use a few bits behind the scenes to map disks to VMs. One of these bits is an annotation on VM disks to “tell” Harvester which VM owns the disk. This causes problems when we attempt a restore of a VM, as the Harvester admission webhook doesn’t like it when trying to bring a VM online attached to a disk with an annotation telling it should be attached to another VM. This can be overcome simply using a Kasten Transform, which removes the annotations upon restore:
cat <<EOF | kubectl apply -f -
kind: TransformSet
apiVersion: config.kio.kasten.io/v1alpha1
metadata:
name: harvesterpvcfix
namespace: kasten-io
spec:
transforms:
- subject:
resource: persistentvolumeclaims
name: harvester_owned-by
json:
- op: remove
path: /metadata/annotations/harvesterhci.io~1owned-by
EOF
Heads up, you may see the path for the Remove operation with a funny character - ~1. This is because the annotation Harvester uses has a forward slash (/), which isn’t ideal in K8s, but fear not, as the character can be replaced with ~1 and will be parsed by Kasten as a forward slash.
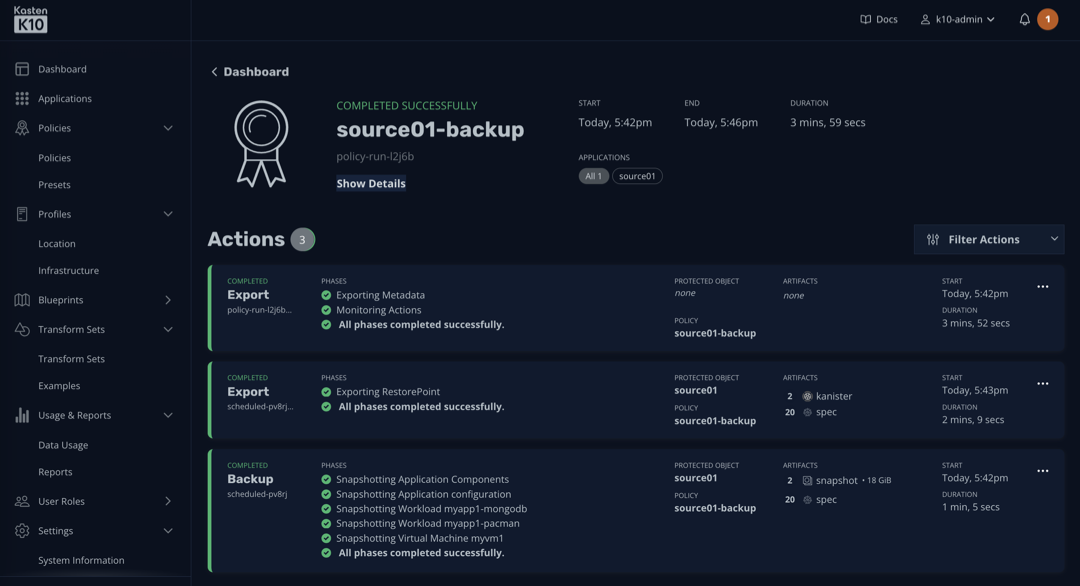
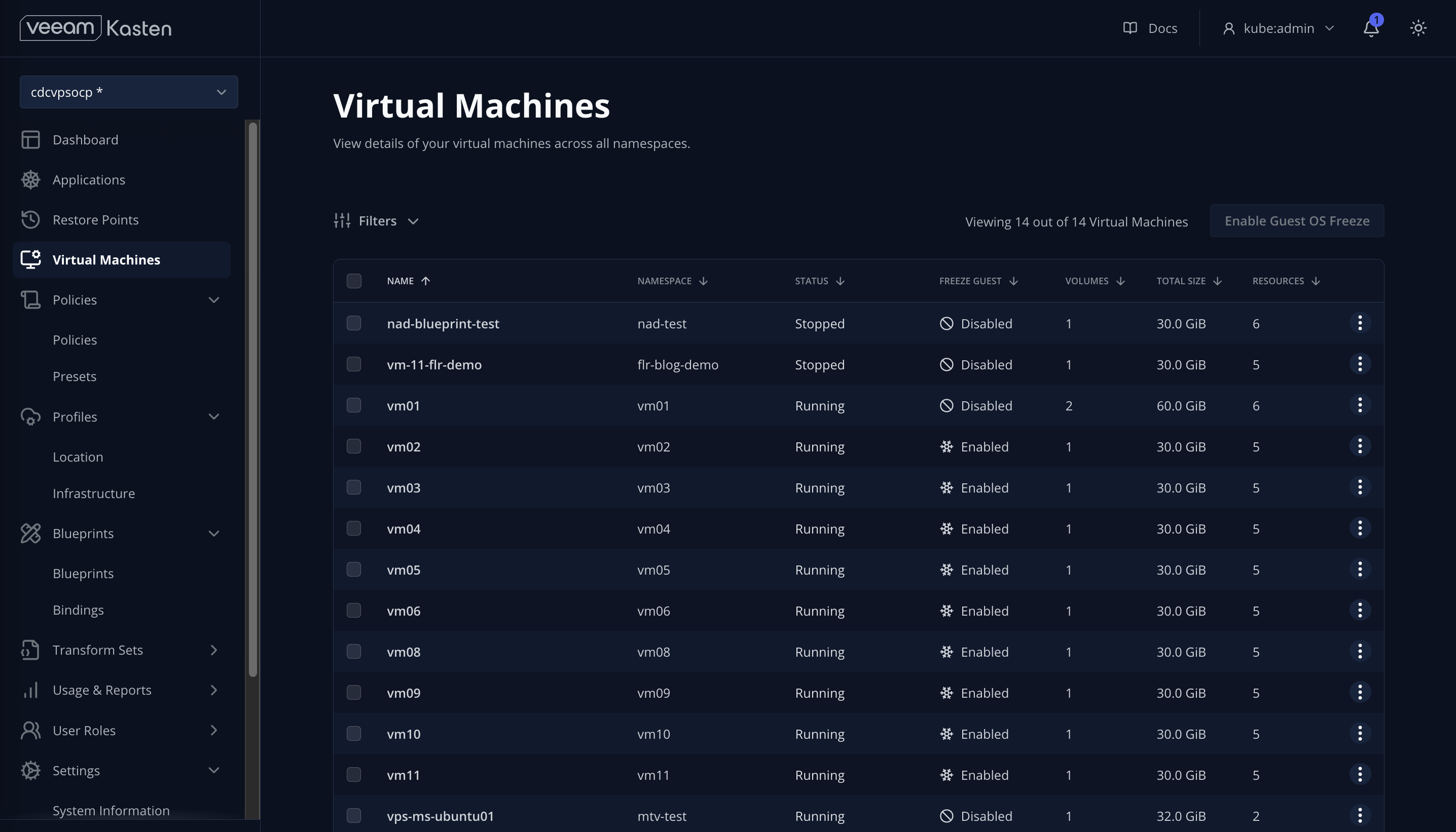
In the example below, we’re protecting both a VM and a cloud native app in the same namespace, source01:

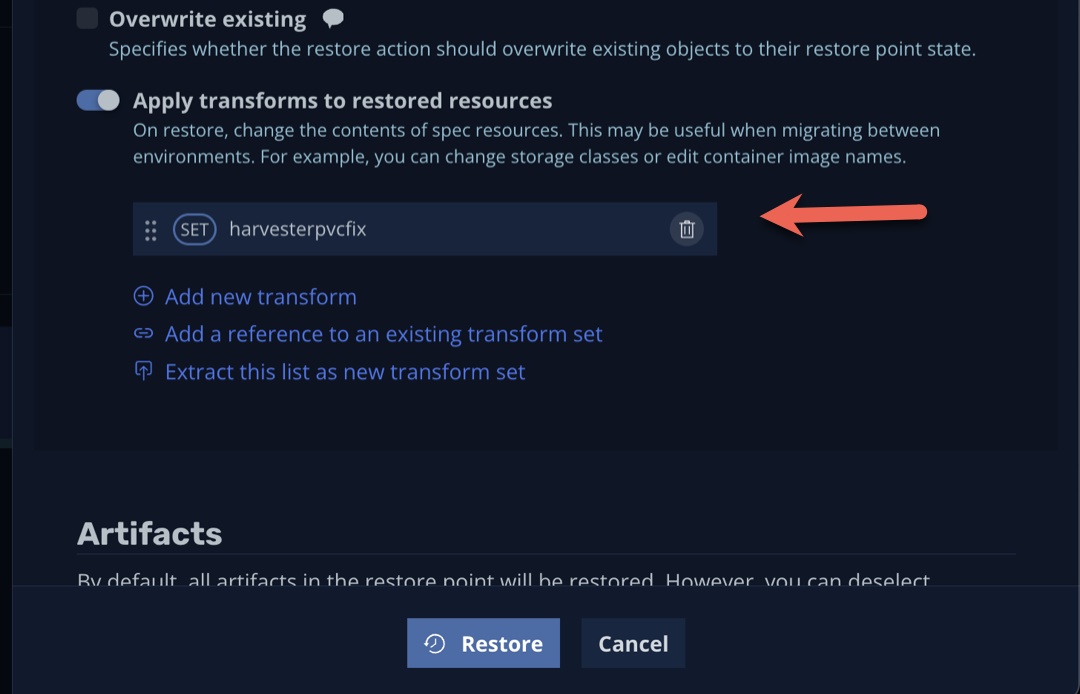
When you restore a VM, ensure that you select the harvesterpvcfix transform to ensure the VM can be restored and booted successfully in Harvester:
And Voilà!, you can now backup, restore, and protect VMs AND applications deployed within Harvester using enterprise-grade backup with Kasten K10.


{kind=link}