






The 3-2-1 rules in the backup world
The 3-2-1 rule in backup strategy is a best practice guideline to ensure data redundancy and protection against data loss. It states:
- 3 Copies of Data: Keep at least three copies of your data. This includes the original data and at least two backups.
- 2 Different Storage Media: Store the copies on at least two different types of storage media. For example, you might keep one copy on a local hard drive and another on a cloud storage service.
- 1 Offsite Copy: Keep at least one copy of the data offsite. This could be in a remote data center, cloud storage, or another physical location
Kasten make no exception, when we backup a PVC we create a local snapshot and we export it to an object storage.
Impact of the 3-2-1 rules on RPO and RTO
Doing a snapshot is often very short and efficient. But the part consisting in exporting it to an object storage can be long if the change rate and the volume are important. The quality of the link and the IO on the worker nodes make also a difference. This has an impact on the RPO.
When it comes to restore, the same is true, restoring from a snap is often short and efficient but restoring from an object storage can be much longer. This has an impact on the RTO.
Why it can be different with Azure
Azure bring 2 features that Kasten can leverage and that fullfill the 3-2-1 rules and reduces drastically the impact on the RPO and RTO :
- Azure has regions, a region is a geographical area that contains one or more data centers.
- You can copy a snapshot from one region to another in Azure using API
Hence your local restorepoint points to local snapshots (as usual) but your remote restorepoint instead of pointing to an object storage points now to snapshots in the other region.
In case of disaster in the source region you can restore very quickly on the remote region.
Overview
This is summarized in this overiew diagram
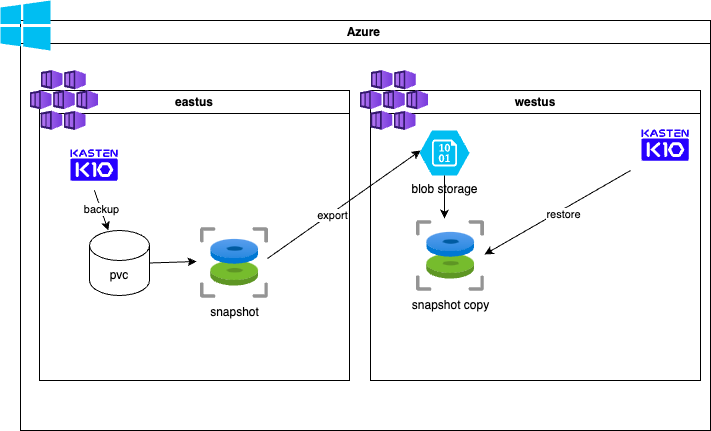
The part export convert an Azure managed disk into a VHD by exporting it to a storage account as a page blob. Page blob are the foundation of Azure IaaS Disks.
In this part Kasten mainly offload the hard work of converting, exporting and recreating the snapshots to Azure. When this process execute you’ll see a vhd container created in the storage account and temporary vhd files created in it.
Then when the snapshot are recreated in the other region the vhd files are removed from the container but now you have snapshots available for a fast restore in the disaster recovery region.
Prerequisite
With this understanding we can list the prerequisite for this approach
- Kasten must have an azure infra profile (for api call to Azure)
- The location profile must be an azure location profile
- The azure location profile must support page blob (Standard and Premium storage accounts, but not Blob Storage)
- The azure location profile must be in the disaster recovery region
- If the snapshot is recreated in a different ressource group then the infra profile need a snapshot contributor role on this resource group
Let’s do it
Install Kasten on both cluster
I have 2 AKS clusters one in eastus and the other in westus region.
Install kasten on the east cluster and do the minimal configuration
aks get-credentials --resource-group ... --name ...
helm repo add kasten https://charts.kasten.io/
hel repo update
k create ns kasten-io
helm install k10 kasten/k10 -n kasten-io
cat <<EOF | kubectl create -f -
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-azuredisk-snapshot-class
annotations:
k10.kasten.io/is-snapshot-class: "true"
driver: disk.csi.azure.com
deletionPolicy: Delete
EOF
Connect to the kasten instance on the eastus cluster
kubectl --namespace kasten-io port-forward service/gateway 8080:80
The Kasten dashboard will be available at: http://127.0.0.1:8080/k10/#/
Create a small app on the cluster in eastus
Let’s create a minimal application that will generate some data regulary following this tutorial with those values
STORAGE_CLASS=managed-csi
SIZE="20Gi"
IMAGE=docker.io/busybox:latest
and to be able to compare RTO and RPO we are going to create a big file from urandom so that we can have significant comparison.
kubectl exec -n basic-app deploy/basic-app-deployment -- dd if=/dev/urandom of=/data/random_file.bin bs=1M count=5120
Once the command returns check the files in the pvc containers
kubectl exec -n basic-app deploy/basic-app-deployment -- ls -alh /data/
You should get something like this
total 5G
drwxr-xr-x 3 root root 4.0K Nov 4 13:01 .
drwxr-xr-x 1 root root 4.0K Nov 4 12:59 ..
-rw-r--r-- 1 root root 667 Nov 4 13:03 date.txt
drwx------ 2 root root 16.0K Nov 4 12:59 lost+found
-rw-r--r-- 1 root root 5.0G Nov 4 13:02 random_file.bin
On eastus let’s create an infra profile
An infra profile is needed in the source cluster because we need to move snapshots from a region to another one. This infra profile hold the credential of a service principal that have a contributor role on the the resource group where the PVC and the snapshots are created.
Discover the resource group of your PV
The easiest way to do this is to simply output an azure disk PV for instance in my case I can do this
kubectl get pvc -n basic-app
I obtain this output
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
basic-app-pvc Bound pvc-1805b525-d50c-452d-9978-f256c44fa37c 20Gi RWO managed-csi <unset> 10m
Which give me the pv pvc-1805b525-d50c-452d-9978-f256c44fa37c
kubectl get pv pvc-1805b525-d50c-452d-9978-f256c44fa37c -o yaml
And I extract this part
volumeHandle: /subscriptions/661b52f9-b122-4600-9f4b-ce4119ez09e4/resourceGroups/mc_rg-cluster-mcourcy1-tf_aks-cluster-mcourcy1-tf_eastus/providers/Microsoft.Compute/disks/pvc-1805b525-d50c-452d-9978-f256c44fa37c
The part I’m interested is the scope of the resource group
/subscriptions/661b52f9-b122-4600-9f4b-ce4119ez09e4/resourceGroups/mc_rg-cluster-mcourcy1-tf_aks-cluster-mcourcy1-tf_eastus
Create a service principal with a contributor role on this resource group
I will create a service principal and add a contributor role
az ad sp create-for-rbac --name mcourcy-fast-restore-demo --role contributor --scopes /subscriptions/661b52f9-b122-4600-9f4b-ce4119ez09e4/resourceGroups/mc_rg-cluster-mcourcy1-tf_aks-cluster-mcourcy1-tf_eastus
This will output this information
{
"appId": "91e0722c-6de7-43fc-db79-0fe3c0a3d999",
"displayName": "mcourcy-fast-restore-demo",
"password": "tZe8Q~WEH7bOLS0fd9iXPDsy9Aw5jwcSWbS9wdRX",
"tenant": "3c77894e-e933-4d5D-kaka-196f3999668c"
}
Create the default infra azure profile
With helm options from the previouss value obtained above a default azure infra profile will be generated
cat <<EOF | helm upgrade k10 kasten/k10 -f -
secrets:
azureClientId: 91e0722c-6de7-43fc-db79-0fe3c0a3d999
azureClientSecret: tZe8Q~WEH7bOLS0fd9iXPDsy9Aw5jwcSWbS9wdRX
azureResourceGroup: mc_rg-cluster-mcourcy1-tf_aks-cluster-mcourcy1-tf_eastus
azureSubscriptionID: 661b52f9-b122-4600-9f4b-ce4119ez09e4
azureTenantId: 3c77894e-e933-4d5D-kaka-196f3999668c
EOF
Navigate to infra profile you should see you’re infra profile
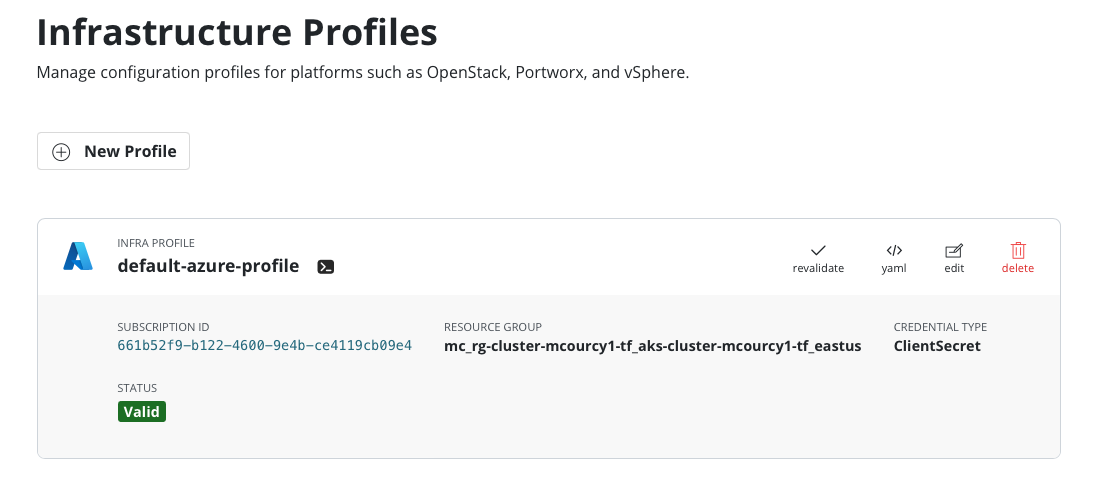
Make sure the service principal can create the snapshot in the resource group of the destination cluster
In order for the destination cluster to pickup the copy of the snapshot and restore I need to create the copy of the
snapshot in the resource group of the destination cluster which is in my case mc_rg-cluster-mcourcy2-tf_aks-cluster-mcourcy2-tf_westus.
Hence I need to provide a snapshot contributor role to the service principal that we already created on this destination resource group.
This assignment must be done with the object id of the service principal and not his client id
client_id=91e0722c-6de7-43fc-db79-0fe3c0a3d999
object_id=$(az ad sp show --id $client_id --query id --output tsv)
Now you can assign the snapshot contributor role on the destination resource group
az role assignment create --assignee $object_id --role 'Disk Snapshot Contributor' --scope /subscriptions/661b52f9-b122-4600-9f4b-ce4119ez09e4/resourceGroups/mc_rg-cluster-mcourcy2-tf_aks-cluster-mcourcy2-tf_westus
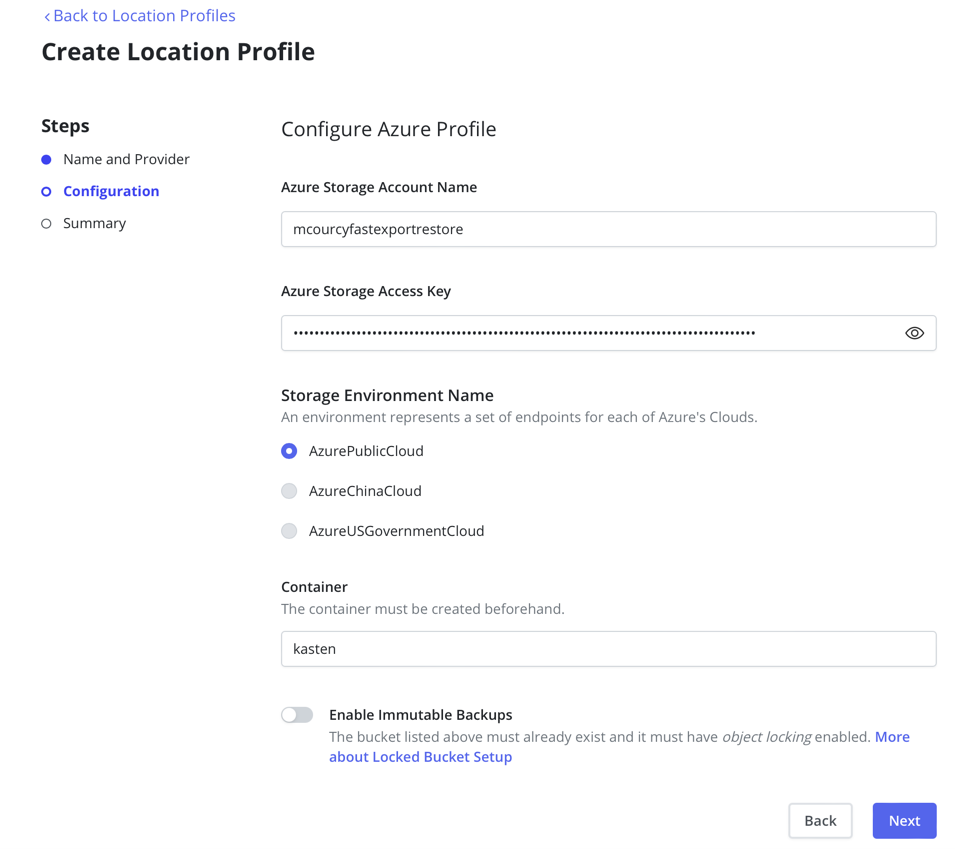
On westus create a storage account that support page blob
Create the storage account with the kasten container
Create a storage account on the destination region, by default standard LRS will support page blob
 In the storage account create a conainer, this container will be used for metadata and portable snapshot.
In the storage account create a conainer, this container will be used for metadata and portable snapshot.
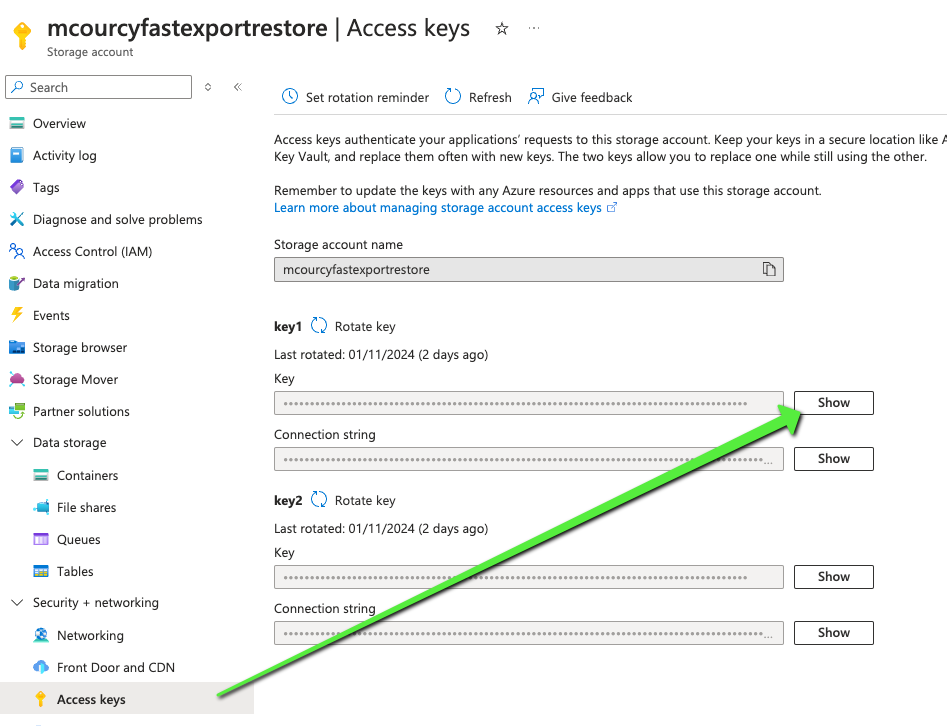
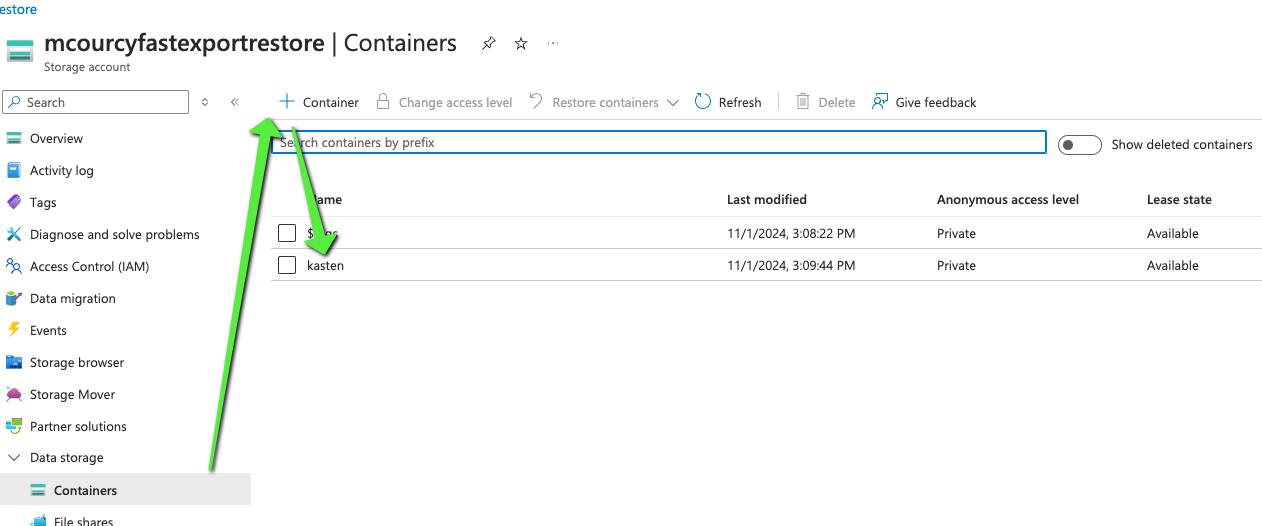 Grab the access key of this storage account you’ll need it for the loaction profile in Kasten
Grab the access key of this storage account you’ll need it for the loaction profile in Kasten
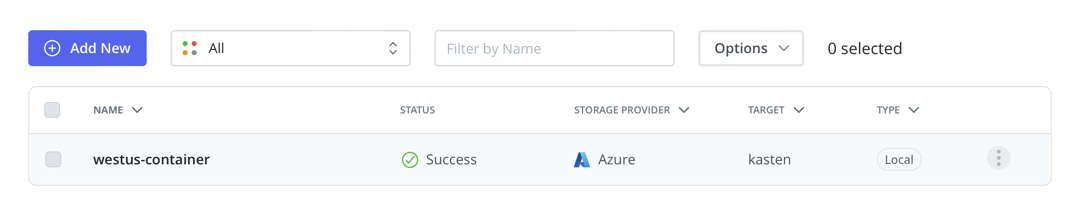
Create the corresponding location profile in kasten
Follow this simple step to create a location profile corresponding to this storage account.
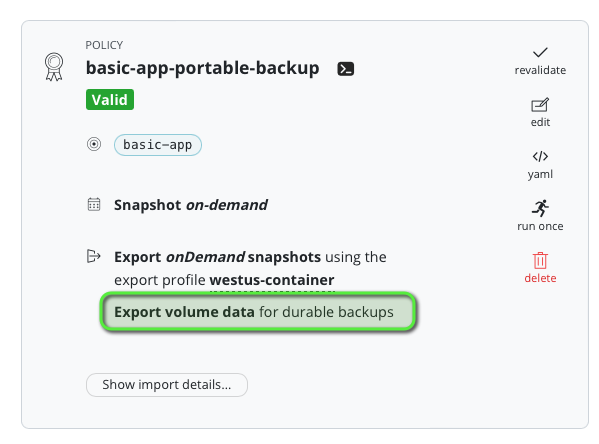
Create two policies for the same basic-app application
In order to compare we’re going to create two policies for the same basic-app application, one will do a regular portable snapshot using our datamover and the other is going to use the cross region snaphot copy feature.
Regular
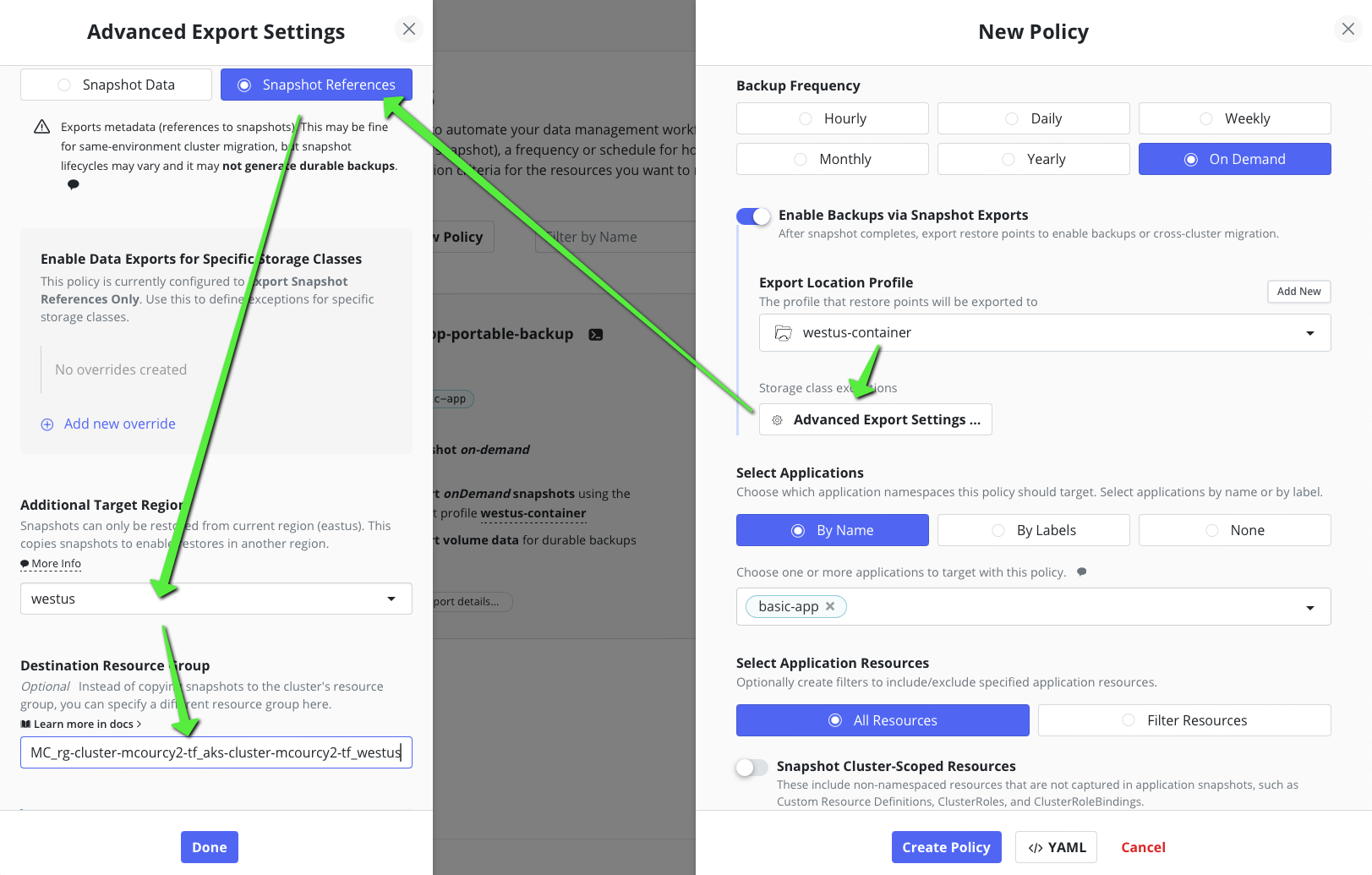
Cross region copy snapshot
For that we use the advanced export action panel, notice that I send the snapshot directly in the resource group of the westus resource group of the destination cluster. But our service principal has been set previously the necessary authorisations.
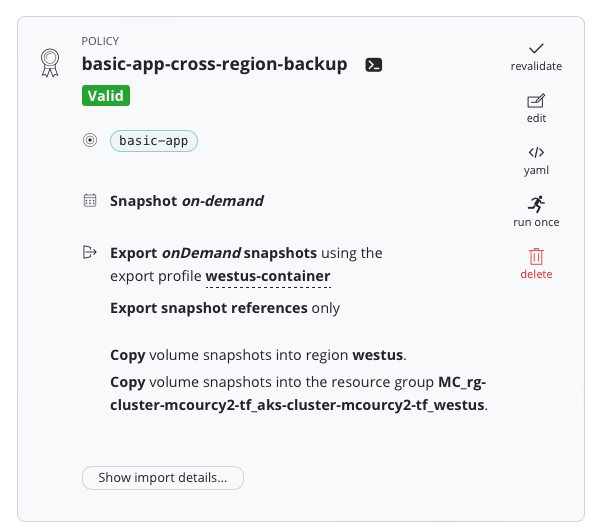
Compare the two policies
Cross region copy snapshots
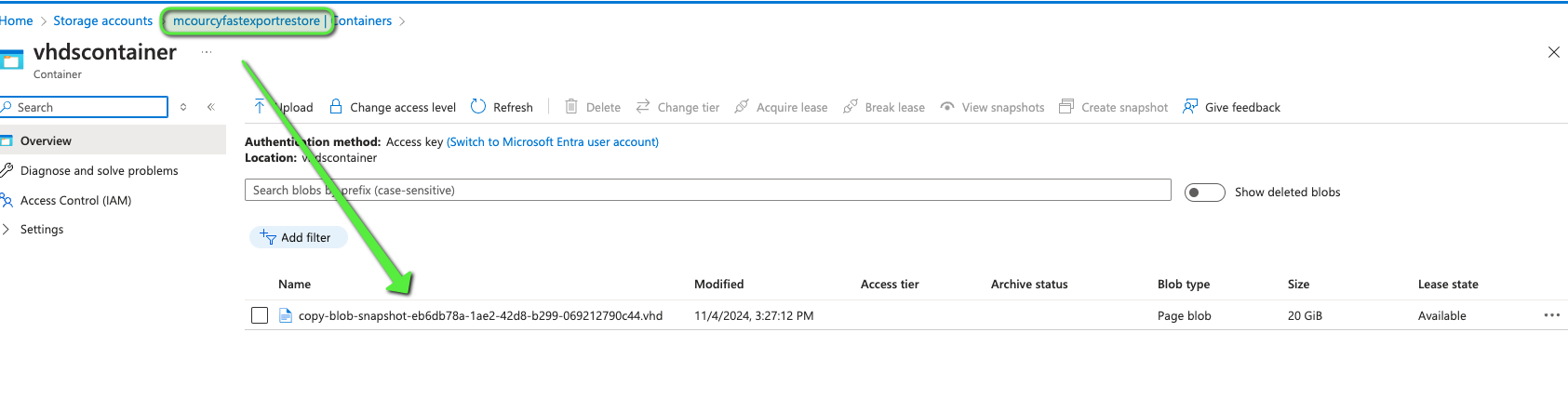
You can see a new container in the storage account called vhdcontainers
When the pvc is uploaded the page blob is removed
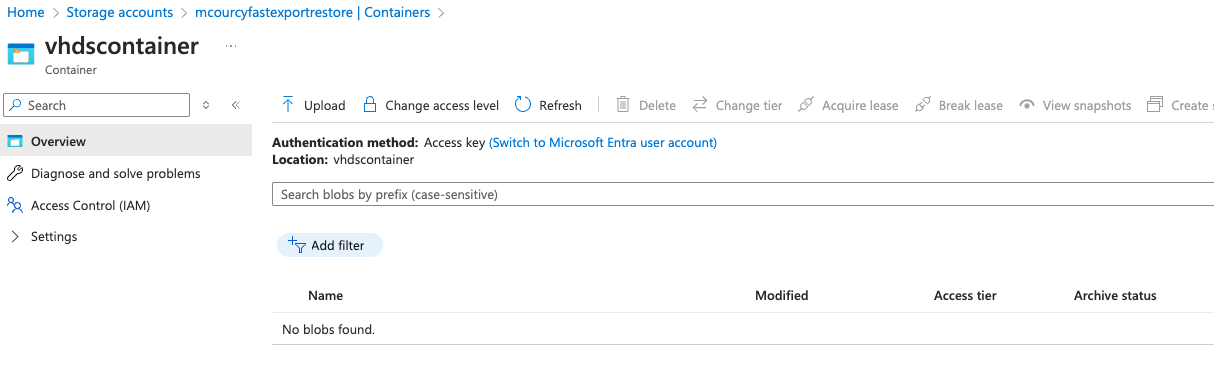
and in the destination resource group we can see the copy of the snapshot
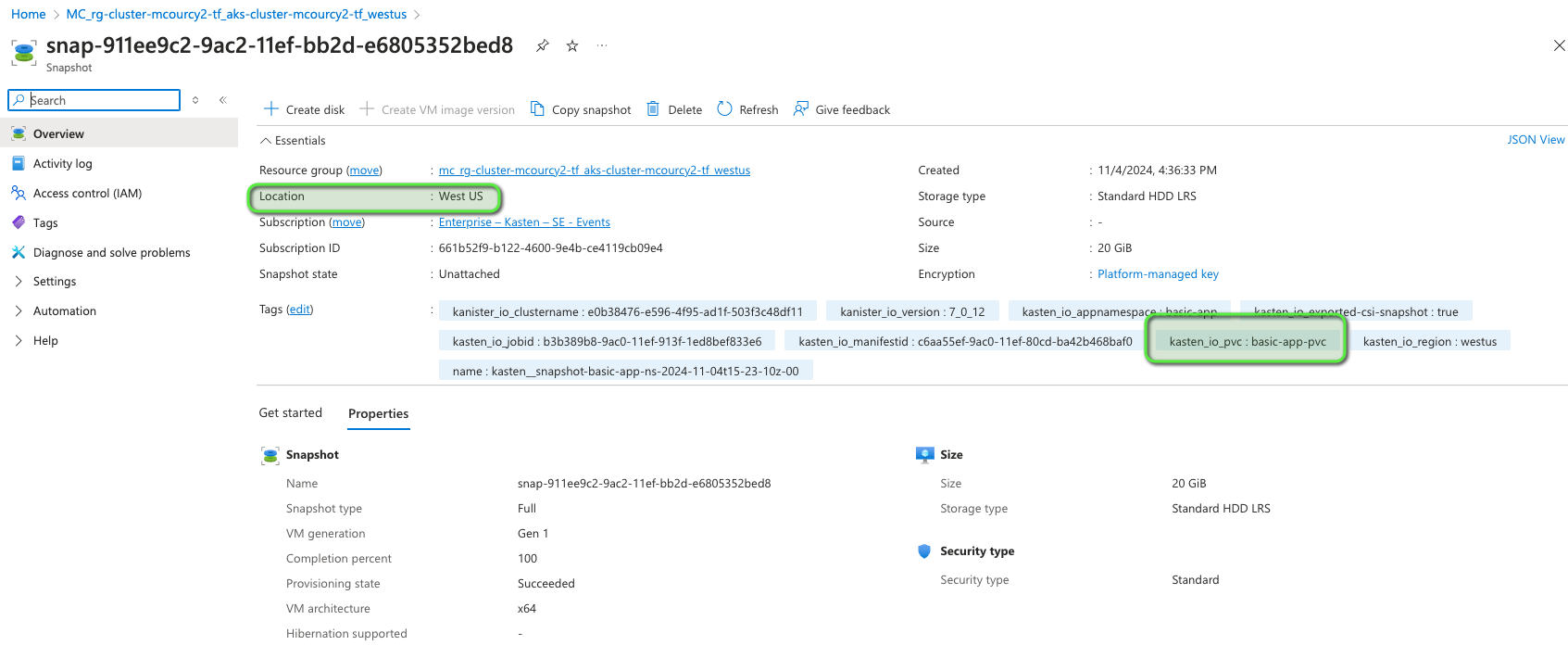
The export time is 6min4s and is constant across backup because we hand off to azure apis and there is no incremental copy
Regular backup
With the regular backup we have an export time wich is shorter the first time 2min38s but very short afterward (42s) because we are incremental and we do very little change.
Restoring on the DR
Restoring is very simple now that the snapshot is already on the resource group that is managed by the csi driver service principal :
- We don’t need an infra profile
- We don’t need to create any extra assignement
- We do need the export details from the cross region policy
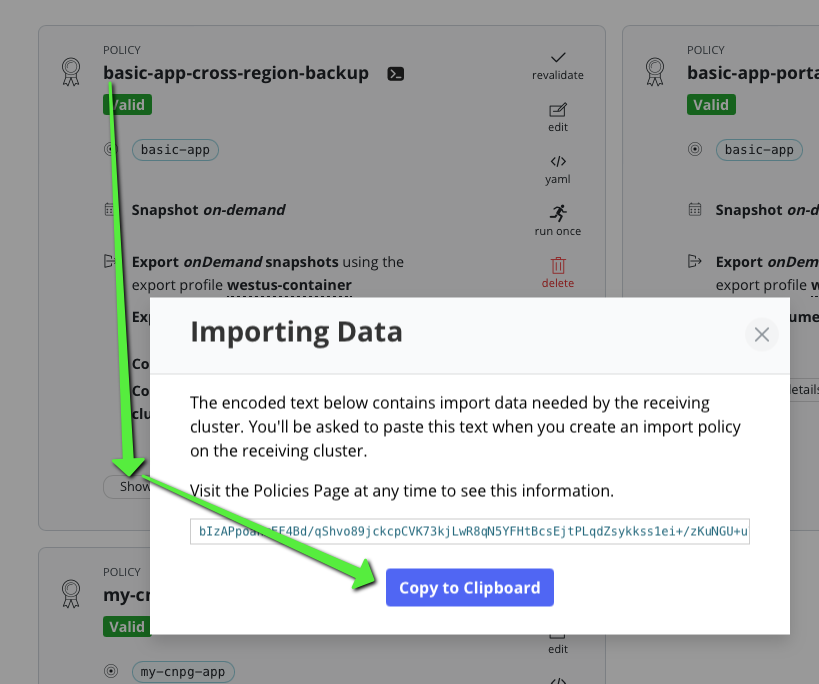
We need to install kasten on the destination cluster (westus) the process is going to be the same as for eastus
aks get-credentials --resource-group ... --name ...
helm repo add kasten https://charts.kasten.io/
hel repo update
k create ns kasten-io
helm install k10 kasten/k10 -n kasten-io
cat <<EOF | kubectl create -f -
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-azuredisk-snapshot-class
annotations:
k10.kasten.io/is-snapshot-class: "true"
driver: disk.csi.azure.com
deletionPolicy: Delete
EOF
Connect to the kasten instance on the eastus cluster
kubectl --namespace kasten-io port-forward service/gateway 8081:80
The Kasten dashboard will be available at: http://127.0.0.1:8081/k10/#/
Recreate the same location profile.
Create an import policy with the export details previously obtained from the source cluster.
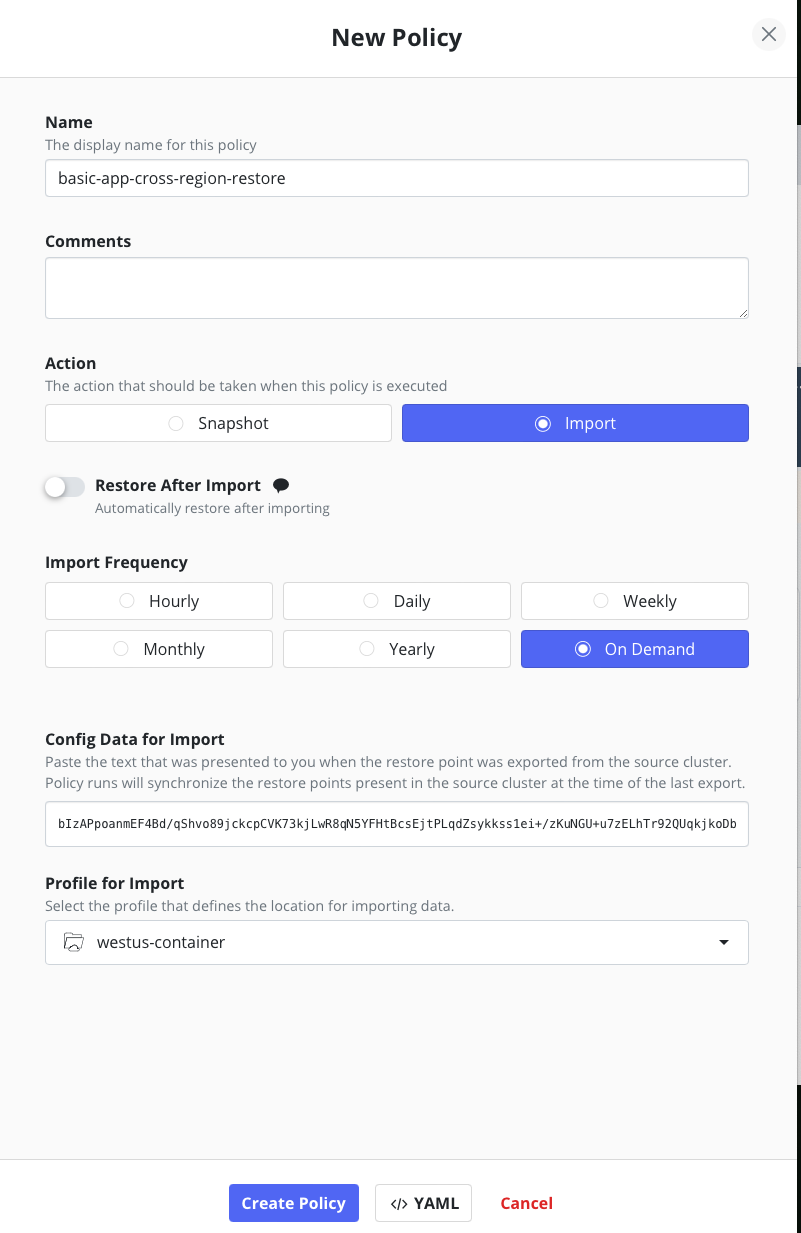
Now select a restore point in the removed application
As you can see the restore is really fast because the snapshot is already available in the resource group.

Conclusion
This solution hand off the cross region export of the snapshots to Azure which coud be interesting if you have big volumes with millions of files, most likely the azure datamover may be more performant than our datamover. But on smaller volume like the one we experiment our datamover is more efficient. Also usinf this approach you loose incrementality and portability.
When it comes to restore you immediately restore from an azure snapshot and in this case you get much better performance in any cases than using our datamover. This is very true for million of files volume.
All in all this is a disaster revovery strategy based on cross region copy and only available for big cloud provider. We also propose something similar for aws.





{kind=link}